目录
一、定义
1.引言
2.分类
(1)按照流的方向分
(2)按操作文件的类型分
3.体系结构
二、字节流(以操作本地文件为例)
1. FileOutputStream 类
(1)定义
(2)写数据的三种方式
Ⅰ. write(int b)
Ⅱ. write(byte[] b)
Ⅲ. write(byte[] b, int off, int len)
(3)换行和续写
Ⅰ. 换行
Ⅱ. 续写
2. FileInputStream 类
(1)定义
(2)循环读取
(3)读数据的两种方式
3. IO流中捕获异常的三种方式
(1)基础写法
(2)JDK7方案
(3)JDK9方案
三、字符集
1.ASCII 字符集
2.GBK字符集
3. Unicode字符集
Unicode 的三种编码方案
(1)UTF-16
(2)UTF-32
(3)UTF-8(最常用)
4.乱码
5. Java 中的编码与解码
四、字符流(以操作本地文件为例)
1. FileReader 类
(1)定义
(2)读数据的两种方式
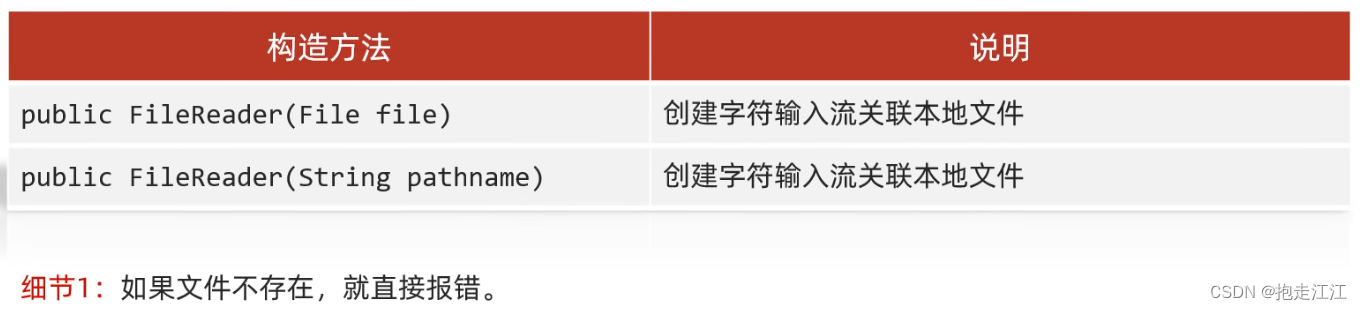
Ⅰ. 空参 read 方法
Ⅱ. 有参 read 方法
(3)底层原理
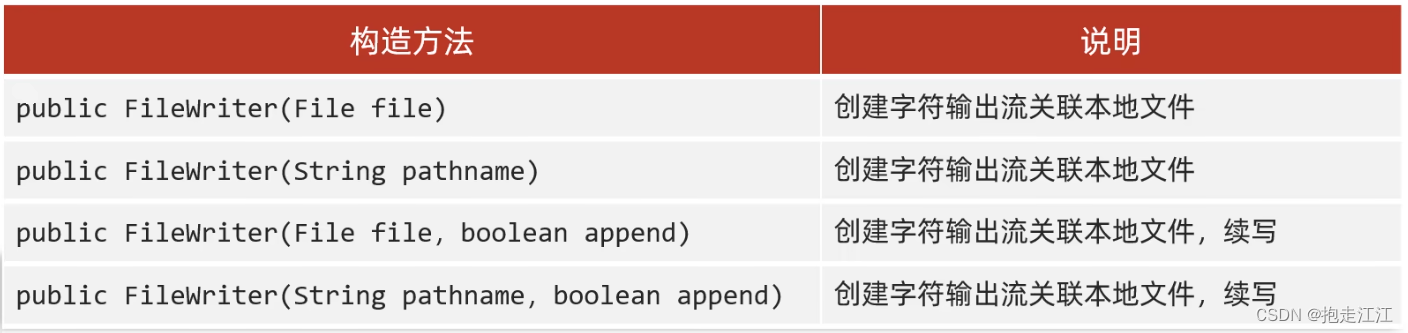
2. FileWriter 类
(1)定义
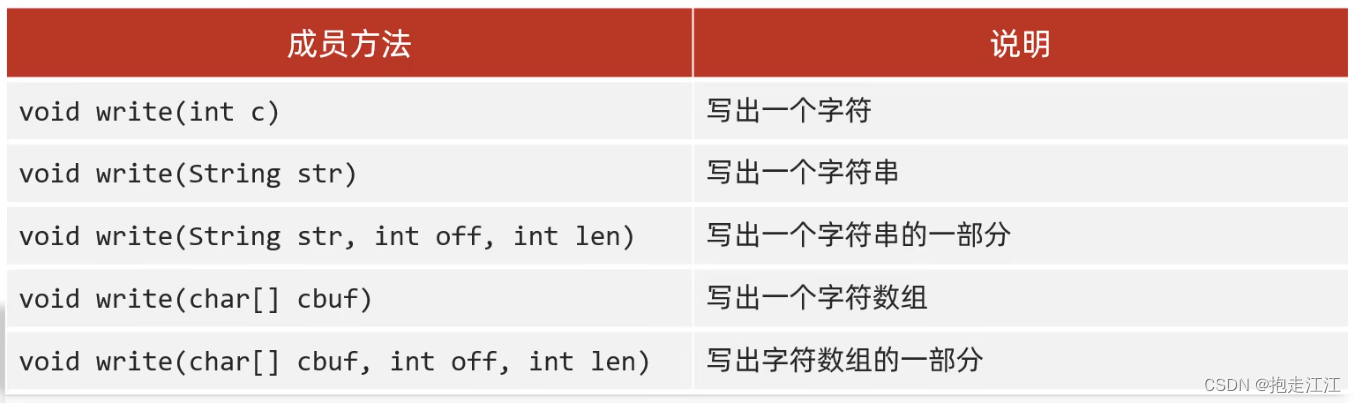
(2)写数据的五种方式
I. write(int c)
编辑
Ⅱ. write(string str) 最常用
Ⅲ. write(char[] cbuf)
(3)底层原理
五、缓冲流
1.定义
2.字节缓冲流
(1)使用
(2)底层原理
3.字符缓冲流
六、转换流
1.引言
2.定义
3.使用
(1)利用转换流按照指定字符编码读取
(2)利用转换流按照指定字符编码写出
七、序列化流和反序列化流
1.序列化流 / 对象操作输出流
2.反序列化流 / 对象操作输入流
3.细节
(1)序列号
(2)transient 关键字
(3)反序列化多个对象
八、打印流
1.字节打印流
(1)构造方法
(2)成员方法
2.字符打印流
(1)构造方法
(2)成员方法
3.标准输出流分析
九、解压缩流和压缩流
1.解压缩流
2.压缩流
(1)压缩单个文件
(2)压缩文件夹
十、常用工具包
1.Commonis-io
2.Hutool
一、定义
1.引言
在执行程序时,数据都存放在内存中,并不能永久化存储。
程序一旦停止,数据就会丢失。
所以为了持久化存储数据,需要将数据进行存档,存在硬盘中的文件中。
① File:表示系统中的文件或则文件夹的路径
缺点:File 类只能对文件本身进行操作,不能读写文件里面存储的数据

② IO流:存储和读取数据的解决方案
I:input(输入、读取) O:output(输出、写出)
作用:用于读写文件中的数据(可以是本地文件,也可以是网络中的数据)
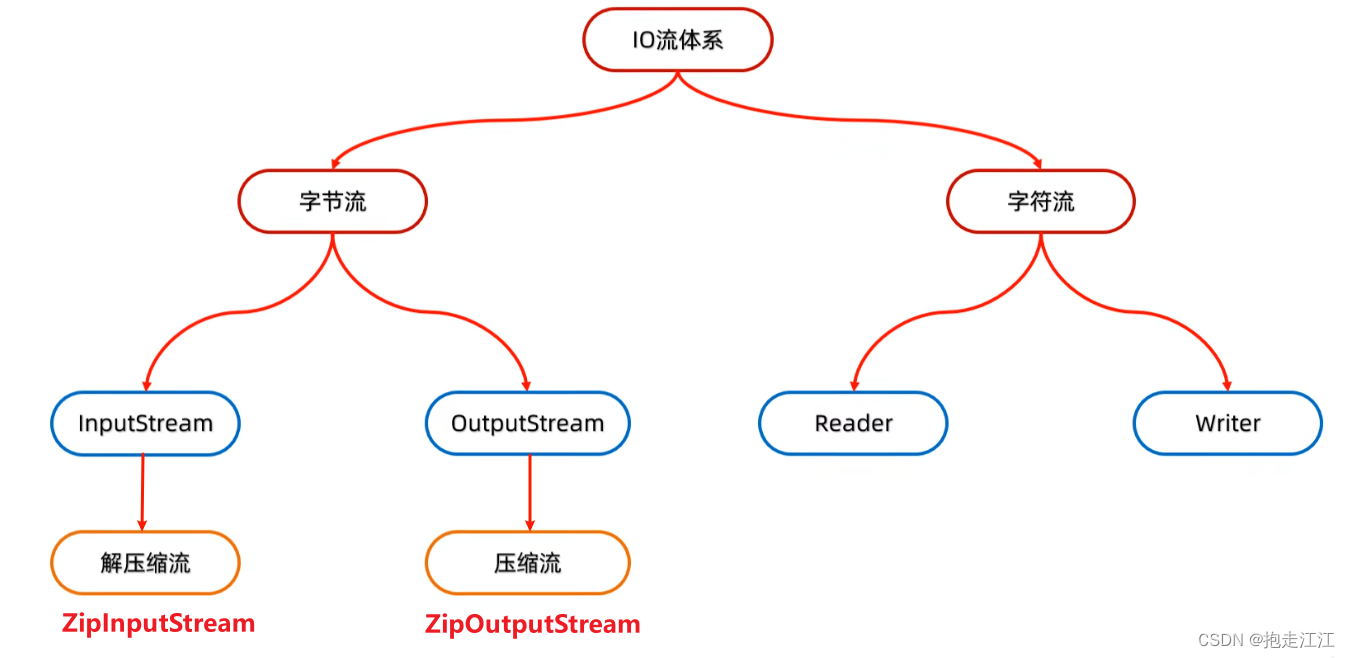
2.分类
(1)按照流的方向分
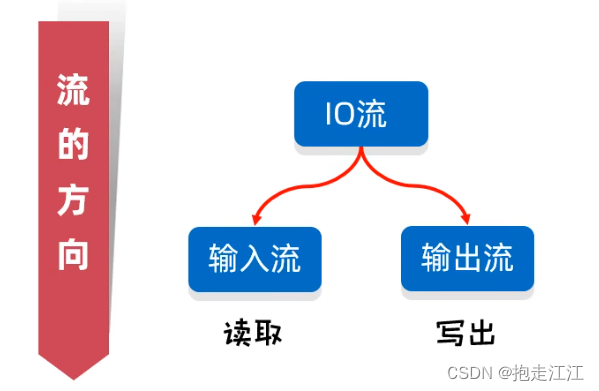
输入流:文件 --> 程序
输出流:程序 --> 文件
(2)按操作文件的类型分
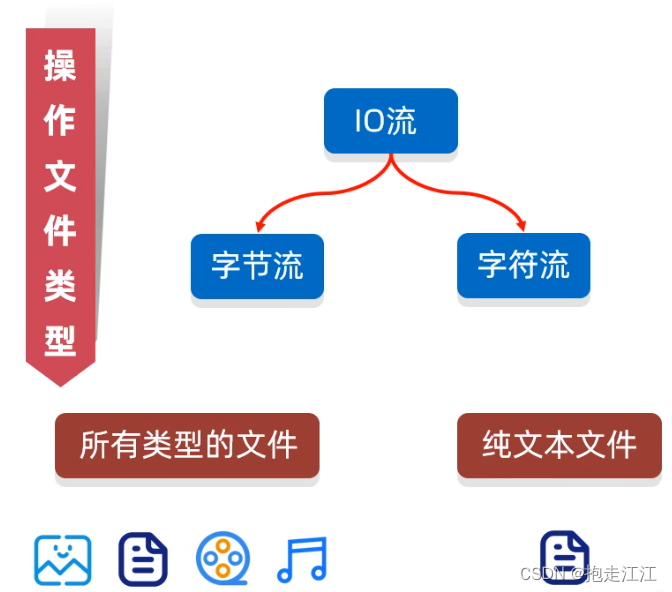
字节流:可以操作所有类型的文件
字符流:只能操作纯文本文件(纯文本文件:Windows系统的记事本打开显示正常的文件)
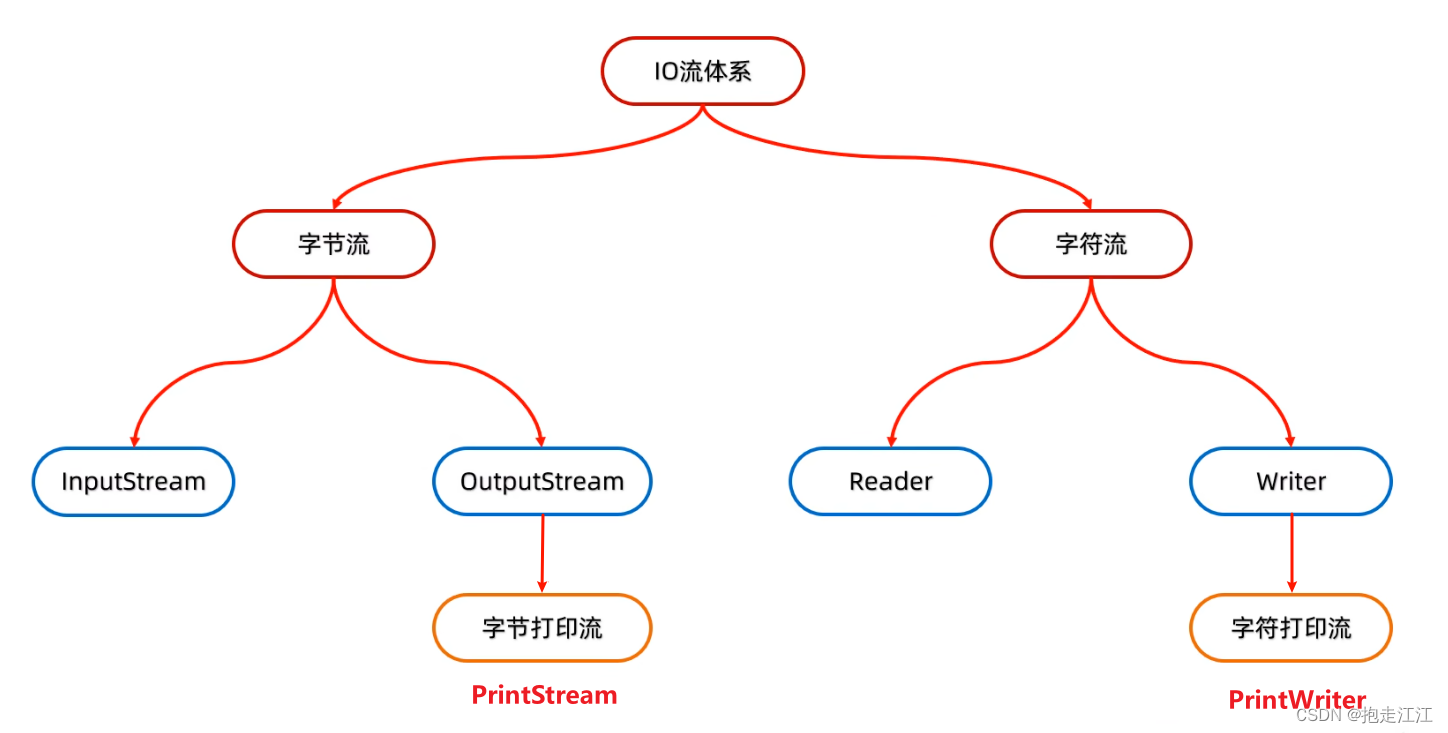
3.体系结构
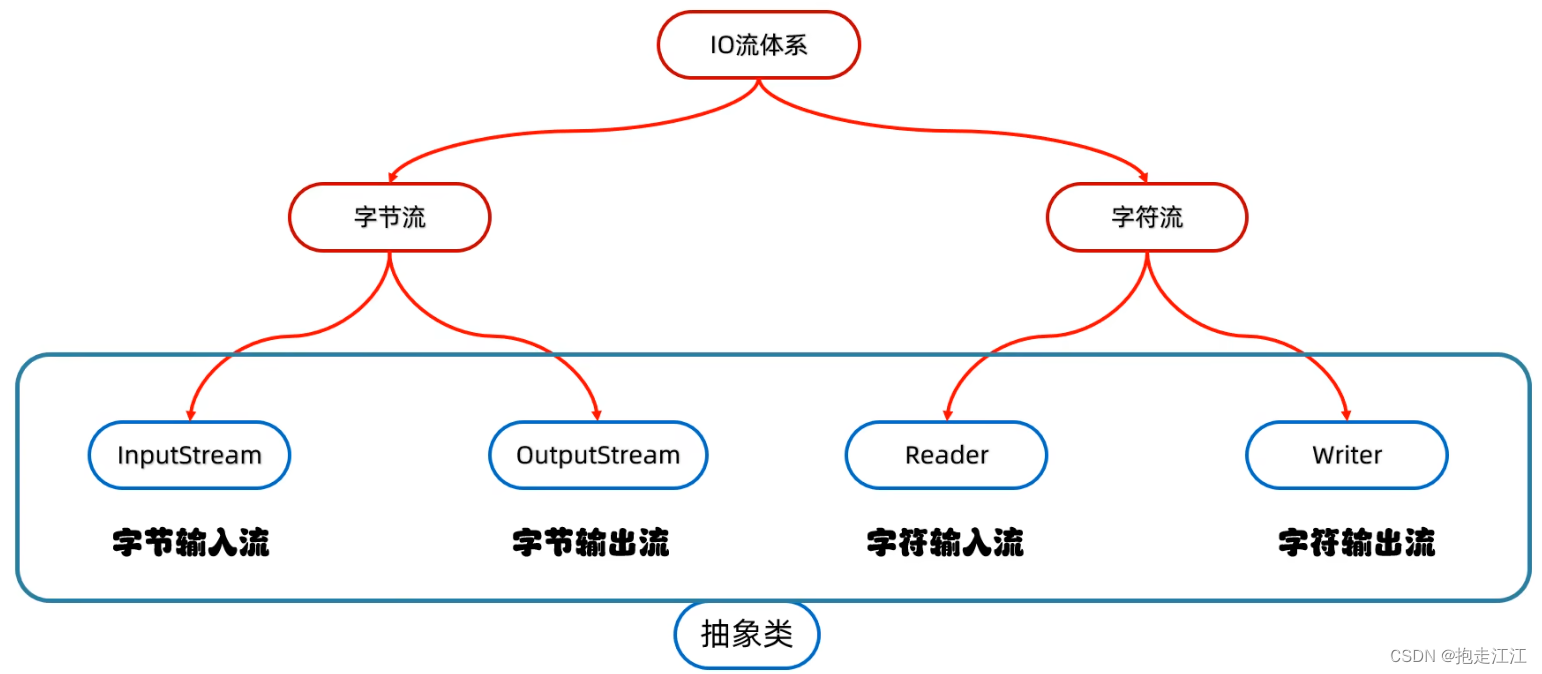
二、字节流(以操作本地文件为例)

1. FileOutputStream 类
(1)定义
作用:操作本地文件的字节输出流,可以把程序中的数据写到本地文件中。
步骤:
① 创建字节输出流对象
② 写数据
③ 释放资源
public class FileDemo1 {
public static void main(String[] args) throws IOException {
//需求:写出一段文字到本地文件中(不含中文文字)
//1.创建对象
FileOutputStream fos = new FileOutputStream("IO\\a.txt");
//2.写数据
fos.write(97);
//3.释放资源
fos.close();
}
}
运行结果:
字符输出流的细节:
Ⅰ. 创建字节输出流对象:
① 参数可以是 字符串表示的路径 或者是 File 对象
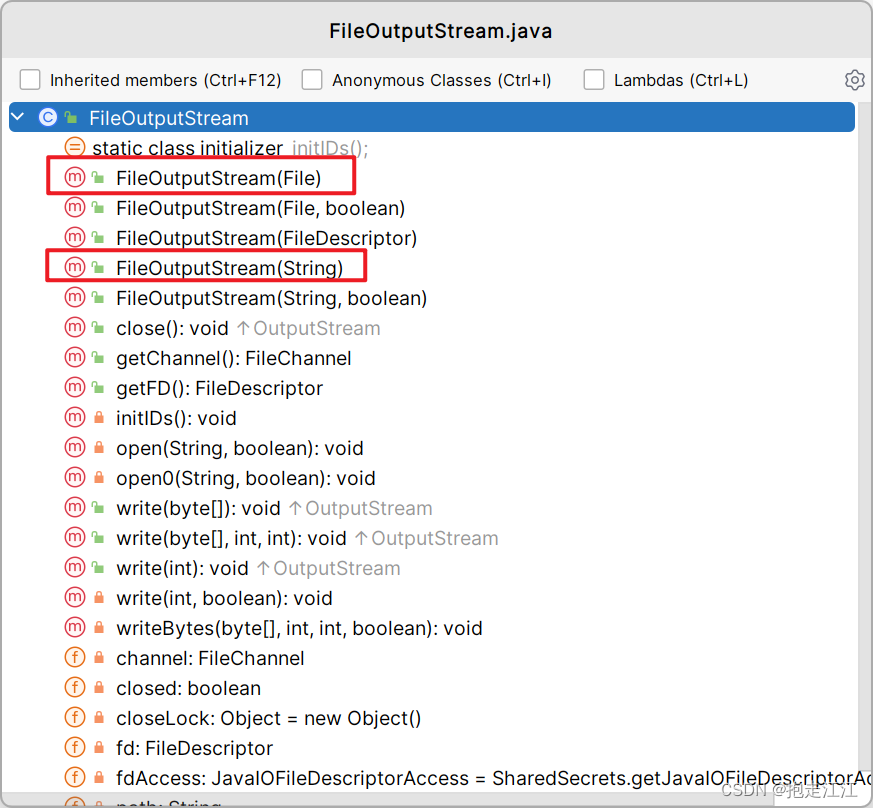
② 如果文件不存在,会创建一个新的文件,但是要保证父级路径是存在的。
③ 如果文件已经存在,则会清空该文件中的数据,重写写出新的数据。
Ⅱ. 写数据:
write 方法的参数是整数,但实际上写到文件中的是整数在 ASCII 码表中对应的字符。
Ⅲ. 释放资源:
每次使用完流之后都必须释放资源,否则程序会一直占用该文件。
如果不解除资源的占用,此时该文件将无法进行其他操作(手动删除等)。
(2)写数据的三种方式

Ⅰ. write(int b)
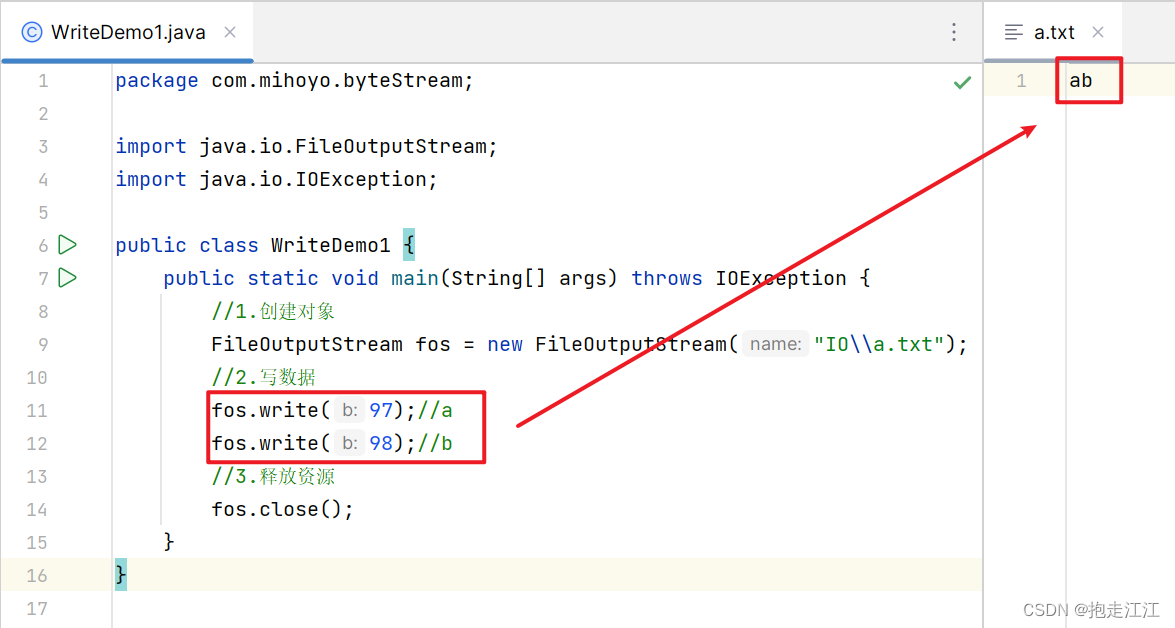
Ⅱ. write(byte[] b)
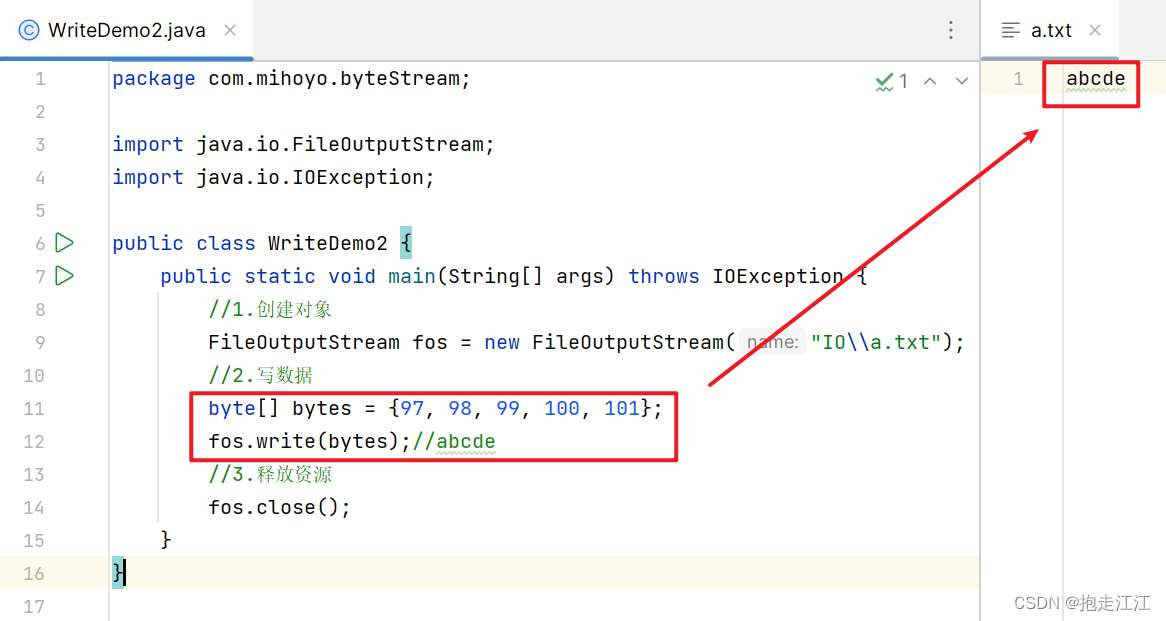
Ⅲ. write(byte[] b, int off, int len)
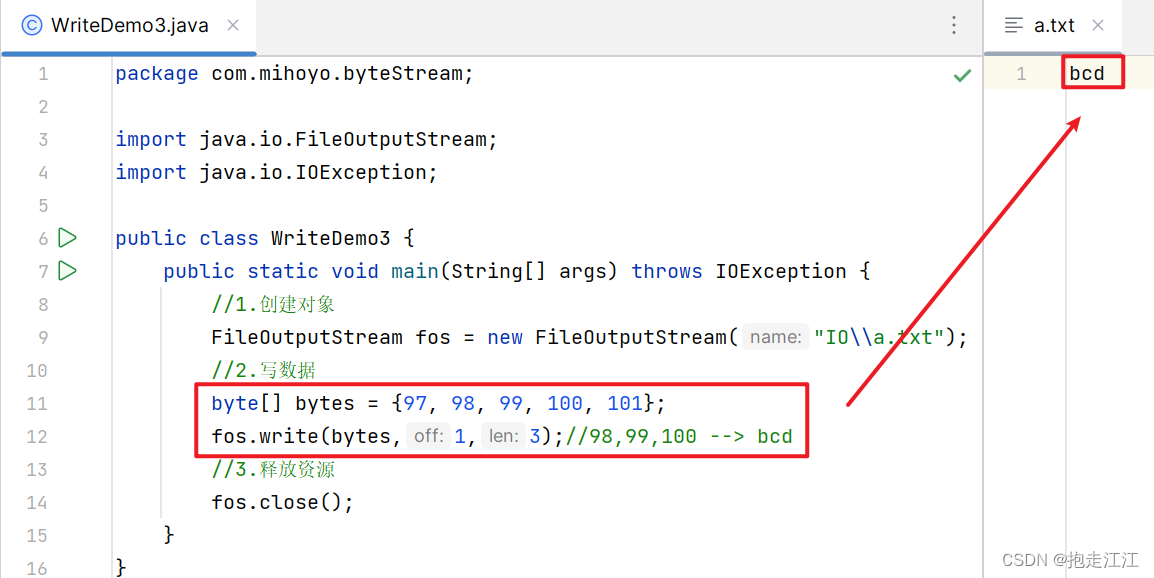
细节:
参数一:字节数组
参数二 off:数组的起始索引
参数三 len:写出数据的个数
Question:如果写出的数据是"Hello World",如何实现?难道一个个查ASCII码表吗?
public class WriteDemo4 {
public static void main(String[] args) throws IOException {
//1.创建对象
FileOutputStream fos = new FileOutputStream("IO\\a.txt");
//2.写数据
String str="Hello World";
//调用getBytes方法将字符串变成字节数组
byte[] bytes = str.getBytes();
fos.write(bytes);
//3.释放资源
fos.close();
}
}
通过 String 类的 getBytes 方法就可以将字符串变成字节数组,再调用 write 方法即可。
(3)换行和续写
Ⅰ. 换行
在不同的操作系统当中,换行符是不一样的:
Windows:\r\n
Linux: \n
Mac: \r
注意:在 Windows 操作系统当中, Java 对回车换行进行了优化。
虽然完整的是 \r\n ,但只写其中一个 \r 或者 \n 都可以实现换行,因为 Java 会在底层进行补全。
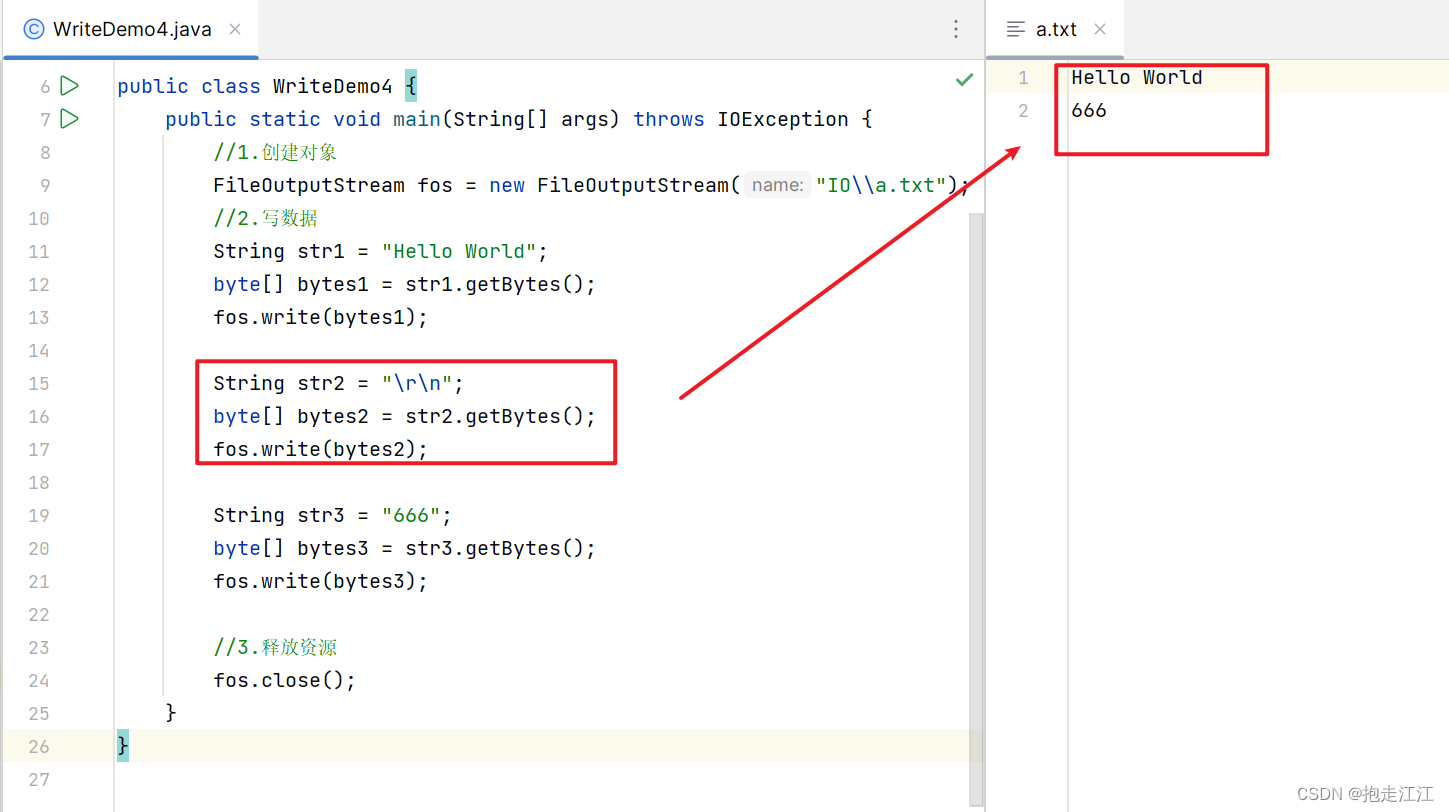
Ⅱ. 续写

在 FileOutputStream 的构造方法中,会调用另一个重载的构造方法,这个方法有一个参数 append
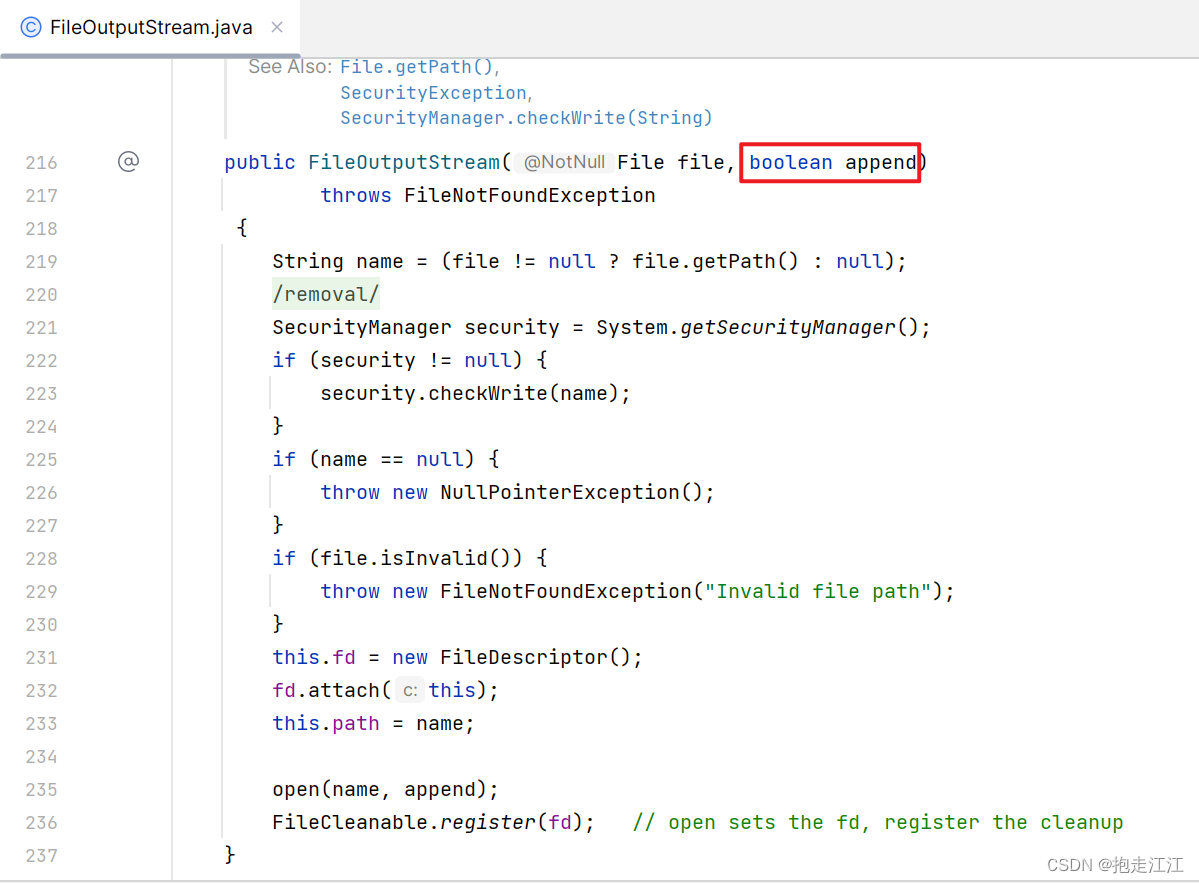
这个 append 表示的就是 是否续写,默认传递的是 false,所以每次都会清空数据进行写出。
如果想要续写,我们只要调用这个构造方法,给 append 传递一个 true 即可。
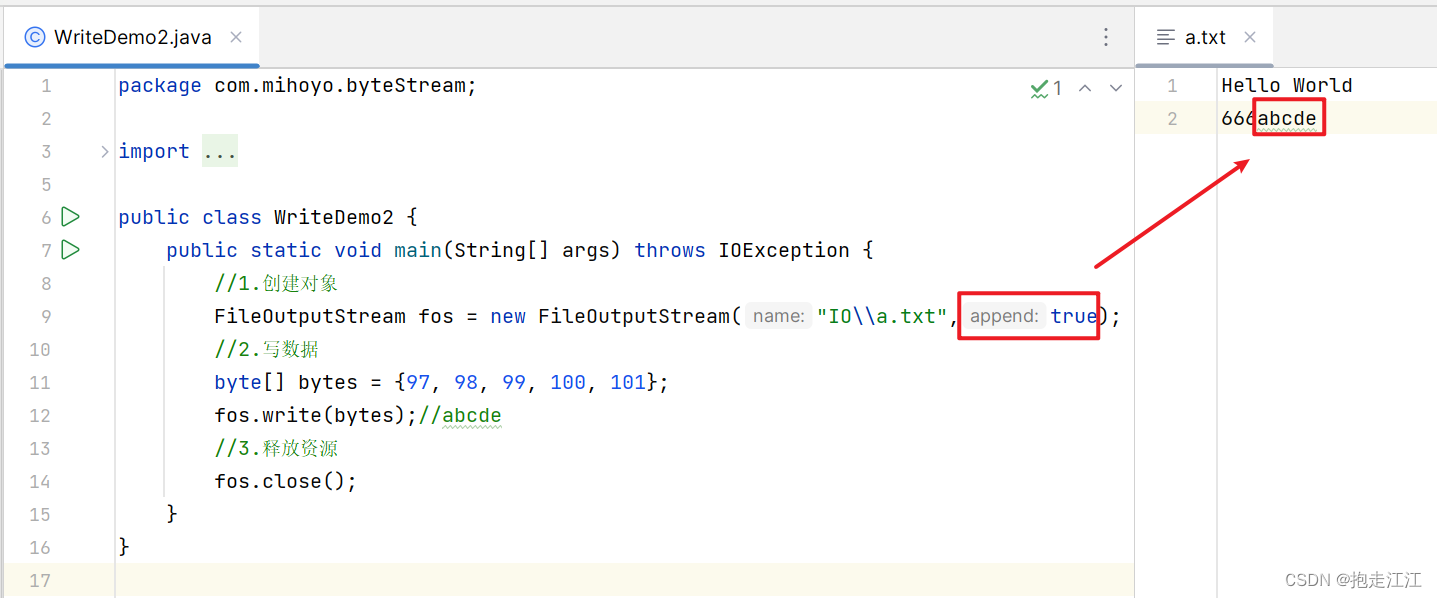
2. FileInputStream 类
(1)定义
作用:操作本地文件的字节输入流,可以把本地文件中的数据读取到程序中来。
步骤:
① 创建字节输入流对象
② 读数据
③ 释放资源

细节:
Ⅰ. 创建字节输入流对象:
如果文件不存在,则直接报错
程序中最重要的是:数据。所以文件不存在,数据就读取不到。
即使像 字节输出流那样,创建一个新的文件,也毫无意义,因为新文件没有数据。
Ⅱ. 读数据
① read 方法负责读取文件中的数据,它会一个字节一个字节的去读,返回该字符的 ASCII 码。
② read 方法读取一个数据,就向后移动一次指针。如果指针到文件末尾了,read 方法就会返回 -1。
Ⅲ. 释放资源:
每次使用完流之后都必须释放资源,否则程序会一直占用该文件。
(2)循环读取
通过上面我们发现,可以通过 read 方法的结果,判断其是否等于 -1,来进一步判断文件是否读完
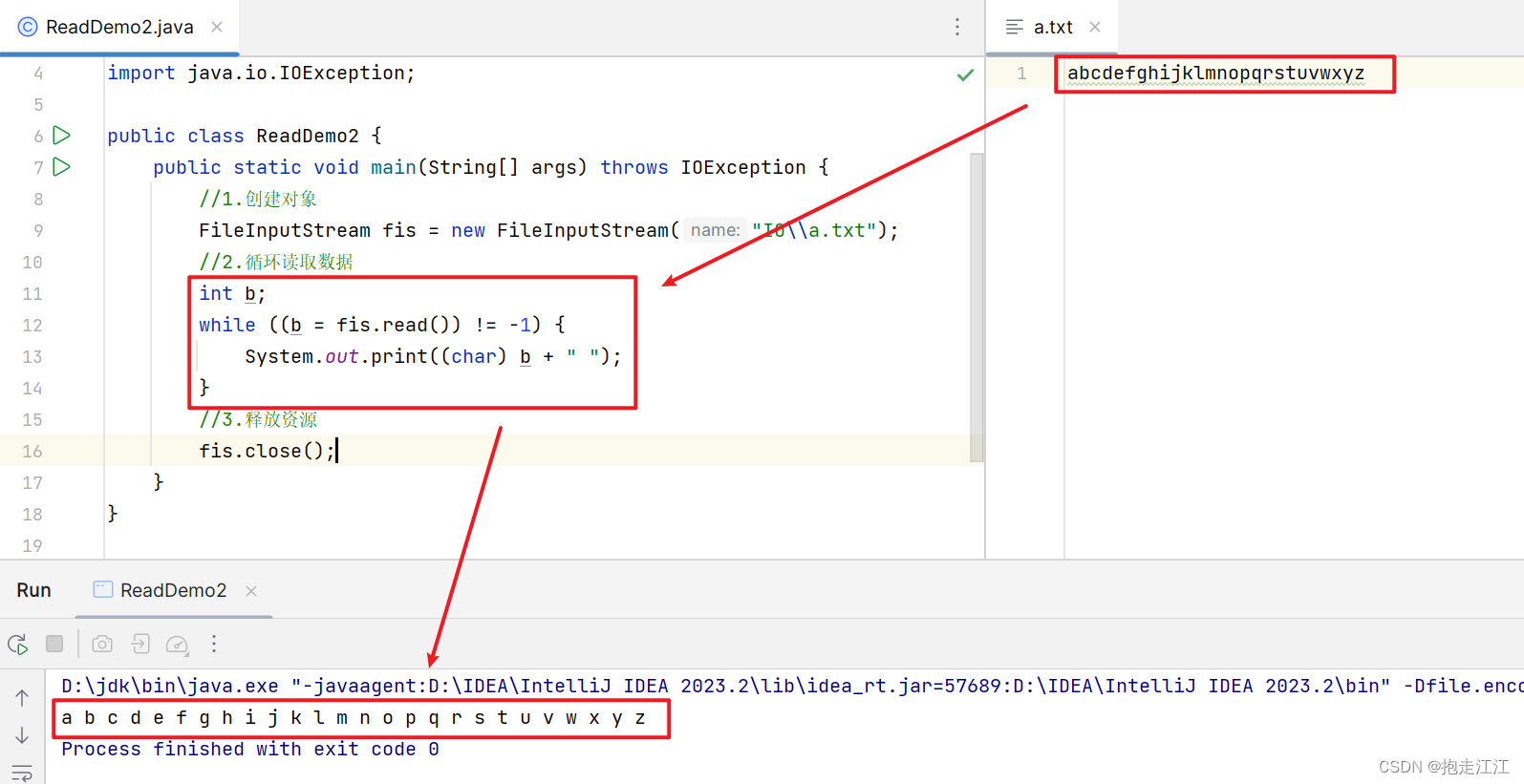
注意:read 表示读取数据,读一次移动一次指针,所以 while 循环中必须用一个变量进行接收。
Test:实现文件拷贝
public class FileCopy {
public static void main(String[] args) throws IOException {
//1.创建对象
FileInputStream fis = new FileInputStream("IO\\a.txt");
FileOutputStream fos = new FileOutputStream("IO\\b.txt");
//2.循环拷贝
int b;
while ((b = fis.read()) != -1) {
fos.write(b);
}
//3.释放资源
fos.close();
fis.close();
}
}
细节:
① 拷贝的核心思想:边读边写
② 释放资源的规则:先开的,后关闭
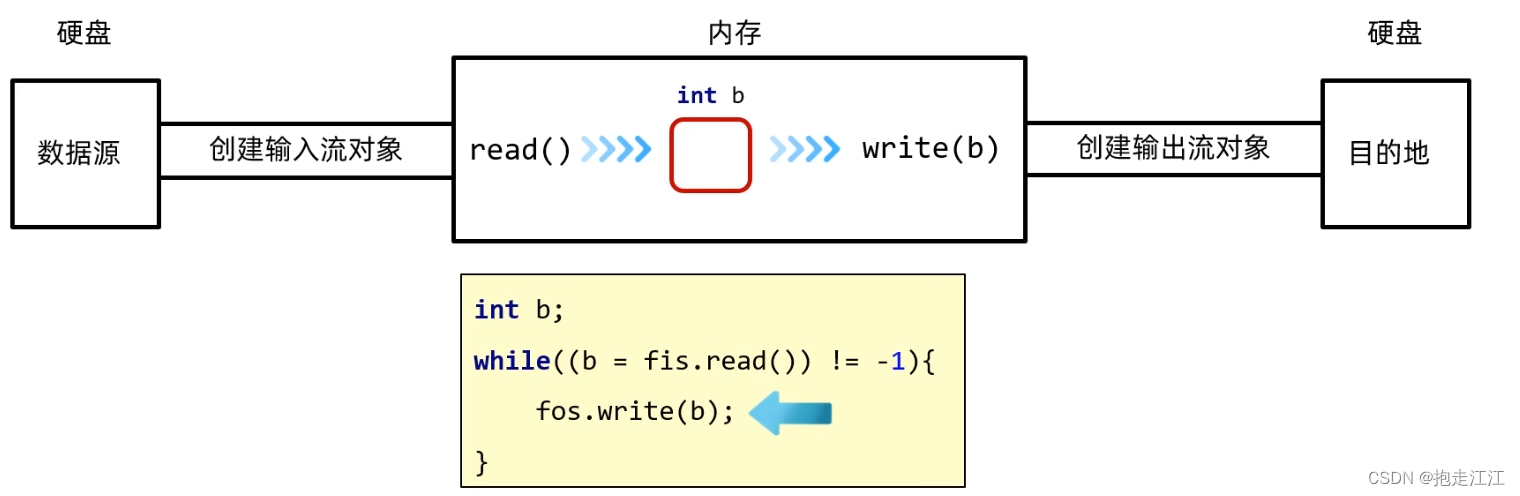
缺点:一次读写一个字节,速度太慢
(3)读数据的两种方式
空参 read 已经介绍,这里主要介绍一次读多个字节的 read 重载方法。

注意:一次读一个字节数组的数据,每次读取会尽可能的把数组装满。
数组大小虽然越大越好,但是数组本身也是占用内存的,数组长度过大可能程序就会直接崩溃。
一般定义数组的大小为 1024 的整数倍,比如 1024 * 1024 * 5 = 5 Mb
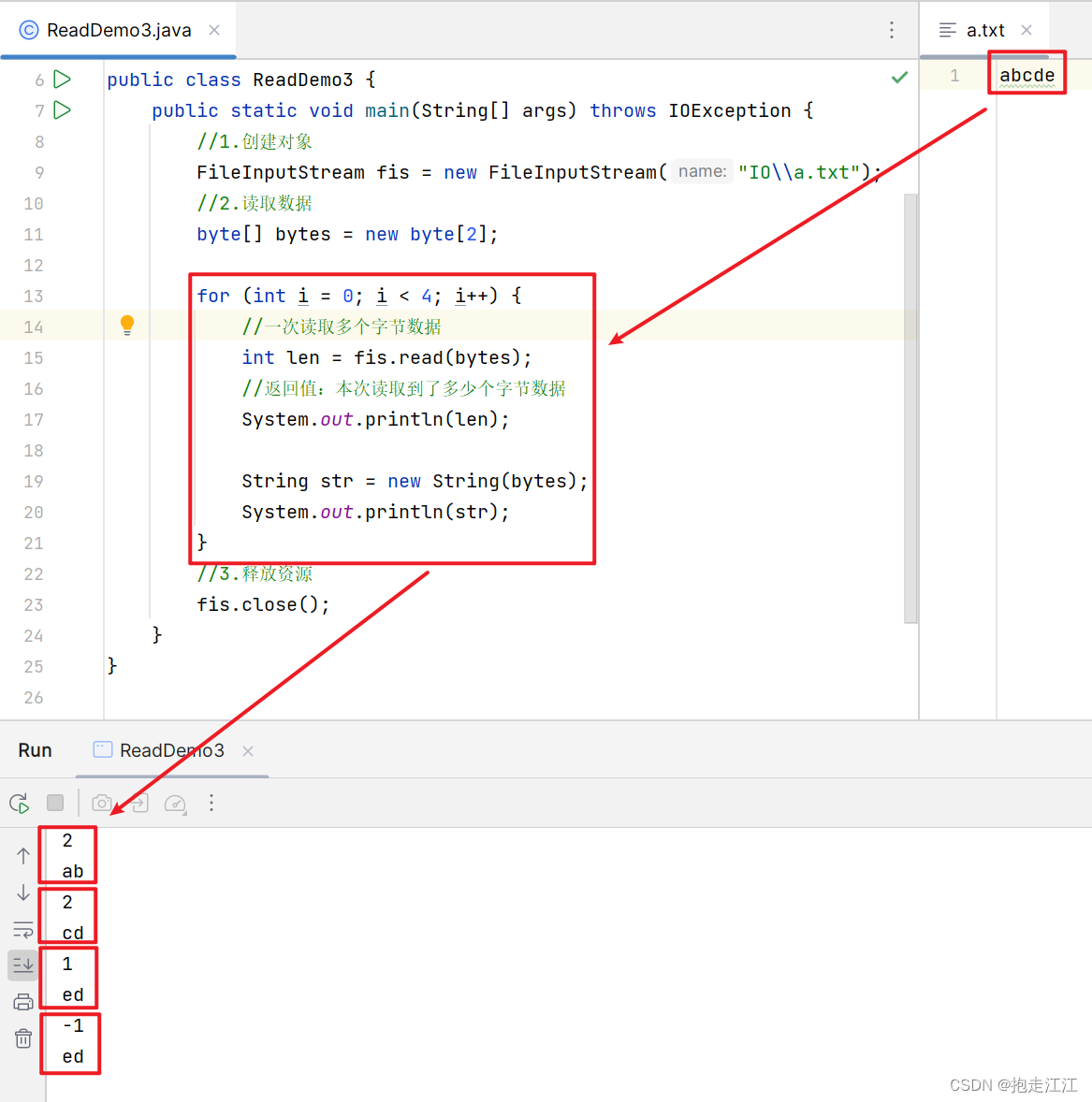
细节:
① 一次读取多个字节数据,具体读多少个,跟数组长度有关,会尽可能的将数组填满。
② 方法的返回值是:本次读取到了多少个字节数据
Question1:为什么第三次、第四次读取到的数据是:ed,第四次读取的长度是 -1?
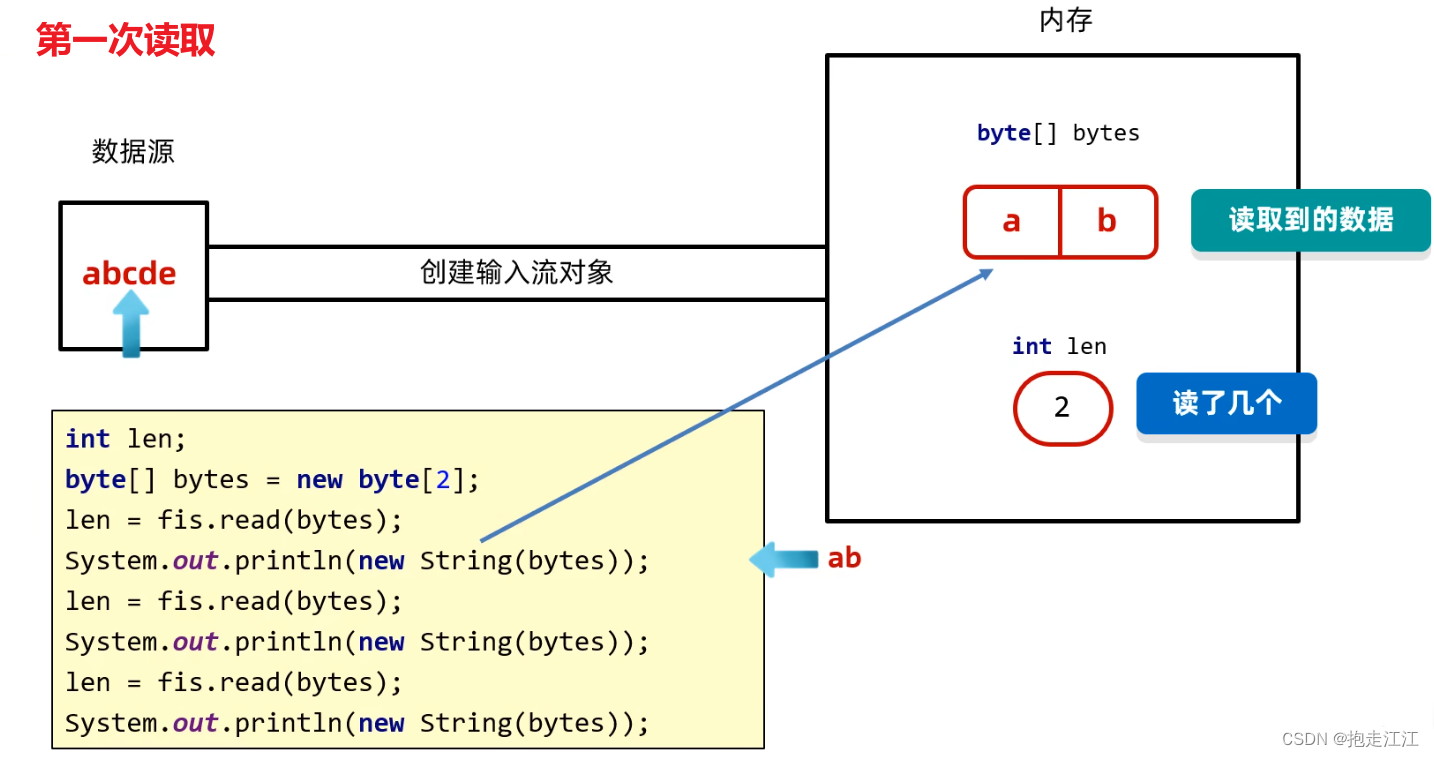
第一次读取,读取到的数据是:ab,指针向后移动两位,指向 c 。
然后会将 ab 存放到 bytes 数组中,len 返回 2。
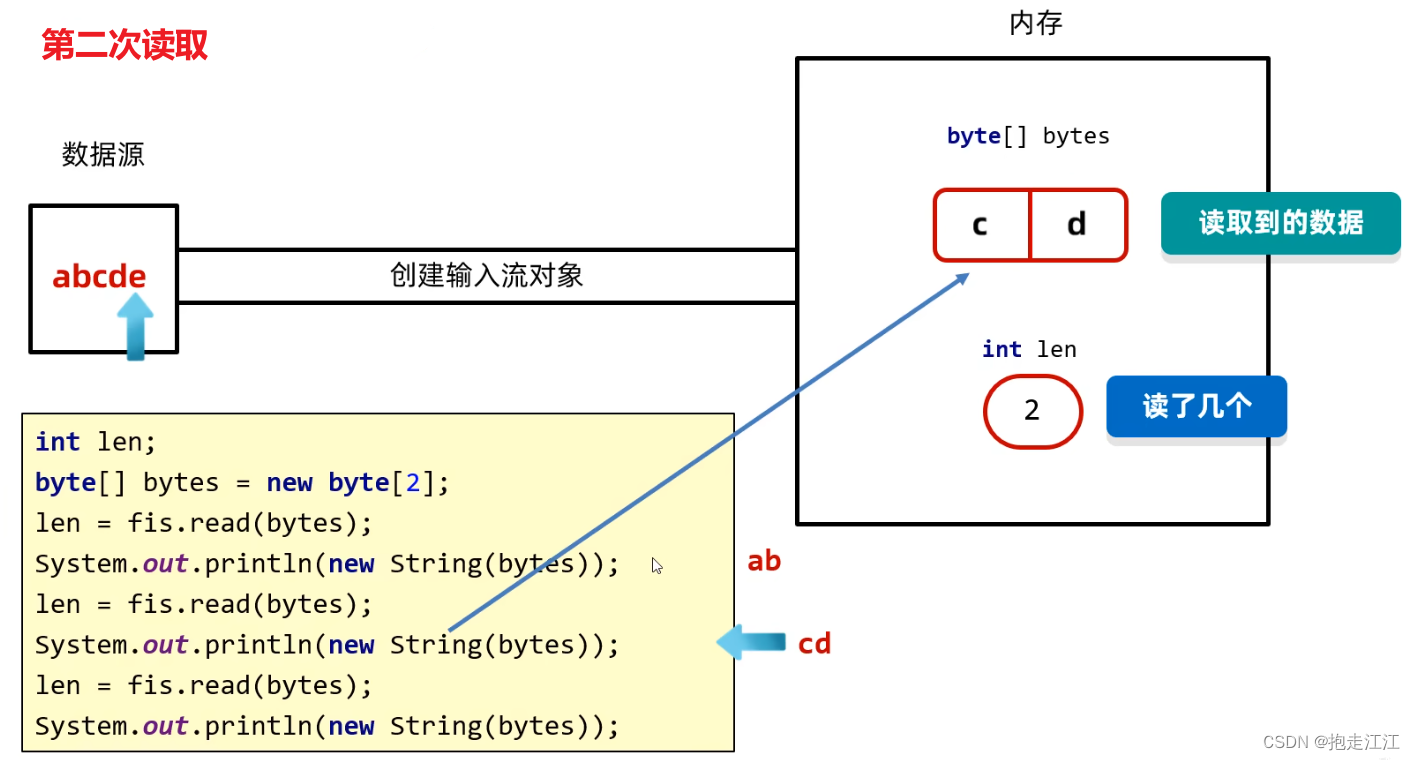
第而次读取,读取到的数据是:cd,指针向后移动两位,指向 e 。
然后会将 cd 存放到 bytes 数组中(进行覆盖),len 返回 2。
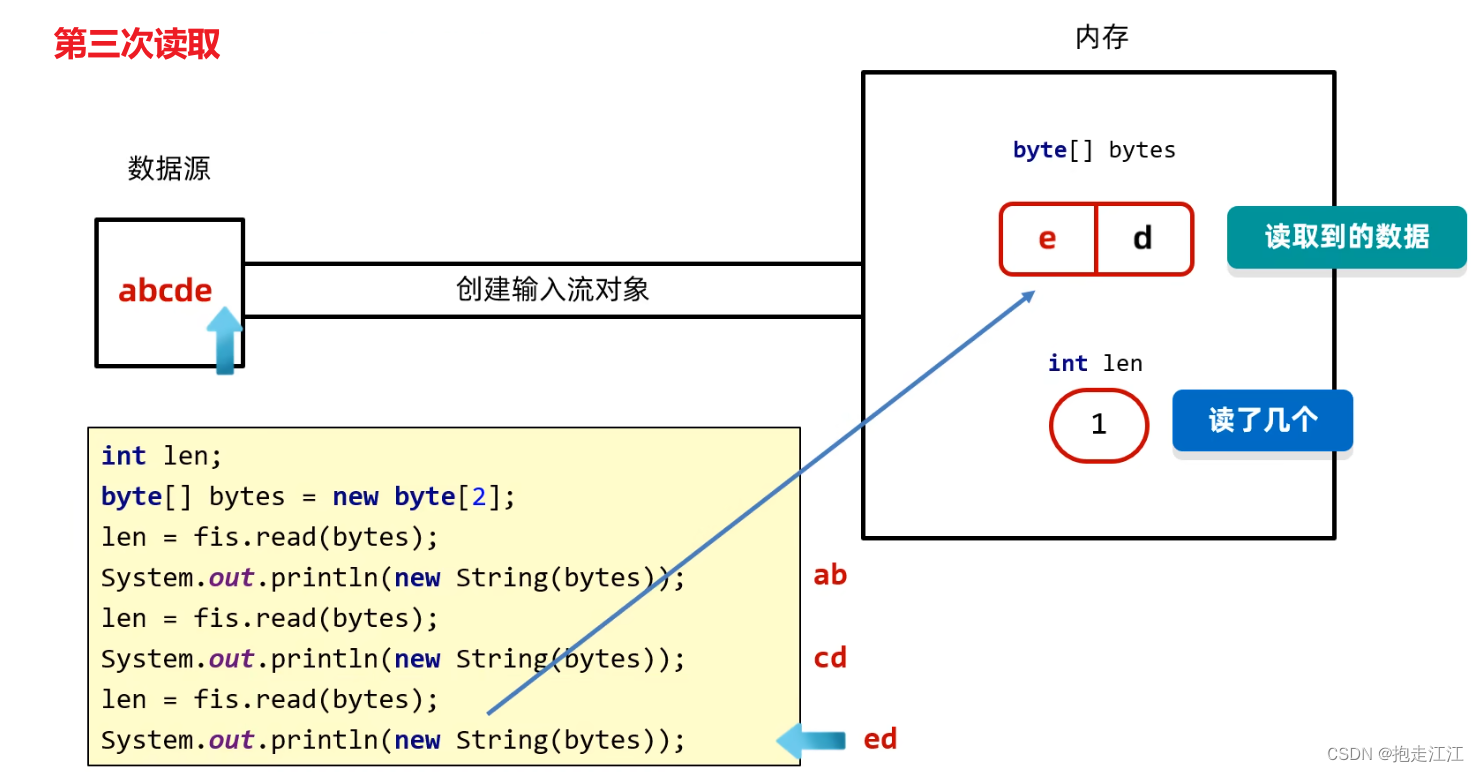
第三次读取,只能读取到一个 e,指针就移到了文件的末尾。
此时会将 e 存放到 bytes 数组中(进行覆盖),len 返回为 1。
由于只读取了一个 e,所以只覆盖了数组的第一个元素,第二个元素 d 仍在数组中,所以打印结果为 ed 。
同理,第四次读取时,读取不到任何元素,那么数组将不会覆盖,打印结果仍然是 ed。
注意:read 方法只要读不到数据,无论是空参还是带有参数(数组)的,都会返回 -1 。
所以第四次读取时,len 返回为 -1。
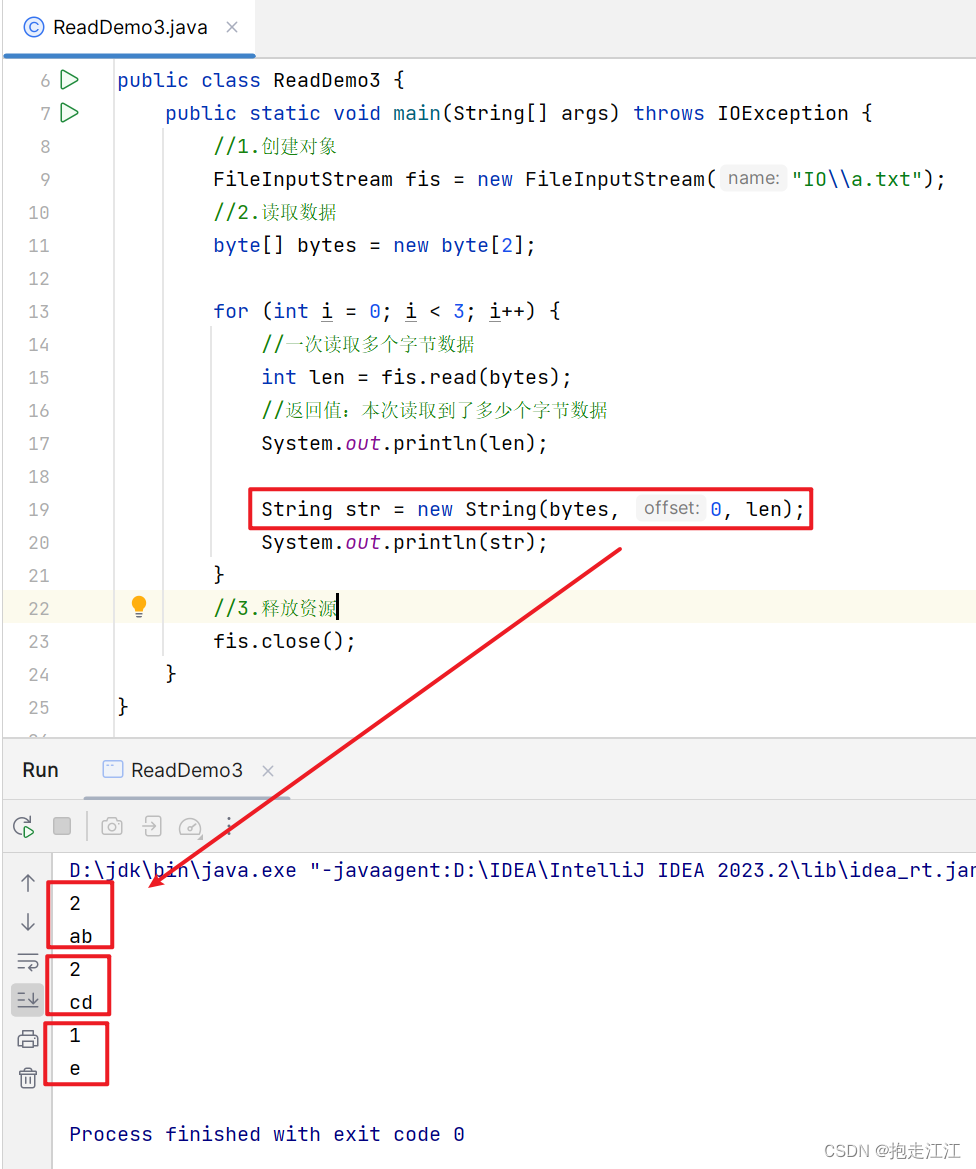
Question2:我希望每次显示的都是自己读到的数据,而没有残留数据,如何修改?
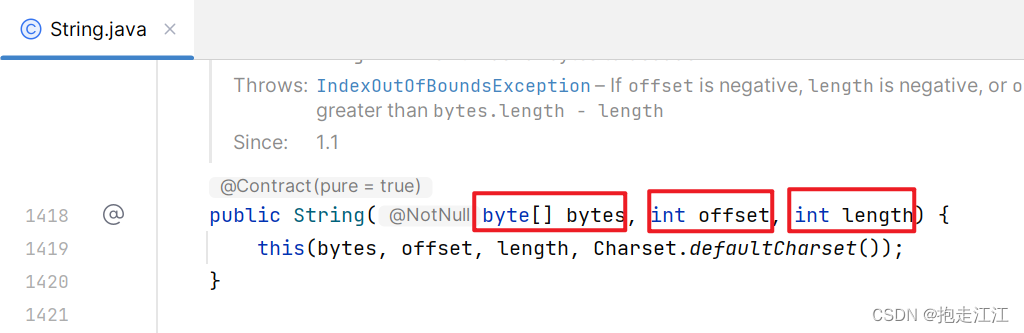
String 类的构造方法中,除了根据 byte 数组创建对象。
还提供了另一个重载的构造方法,可以设置数组的起始索引,和元素的长度。
即从数据的 offset 索引开始,将 length 个元素,变为一个字符串。
3. IO流中捕获异常的三种方式
对于上述代码中产生的异常,我们采用的都是抛出处理 throws。
如果使用捕获异常,try - catch,该如何书写呢?
(1)基础写法

如果将所有代码,都放入 try 中,这会产生一个问题:
因为三个语句都可能发生异常,如果第二条语句 write 方法产生了异常,close 方法将直接跳过。
这时就会造成资源没有释放的问题。

我们可以使用 捕获异常的完整格式:try - catch - finally
特点:finally 中的代码一定会被执行,除非 JVM 停止。
但这样书写,又会产生另一个问题:fos 是一个局部变量,finally 中访问不到。
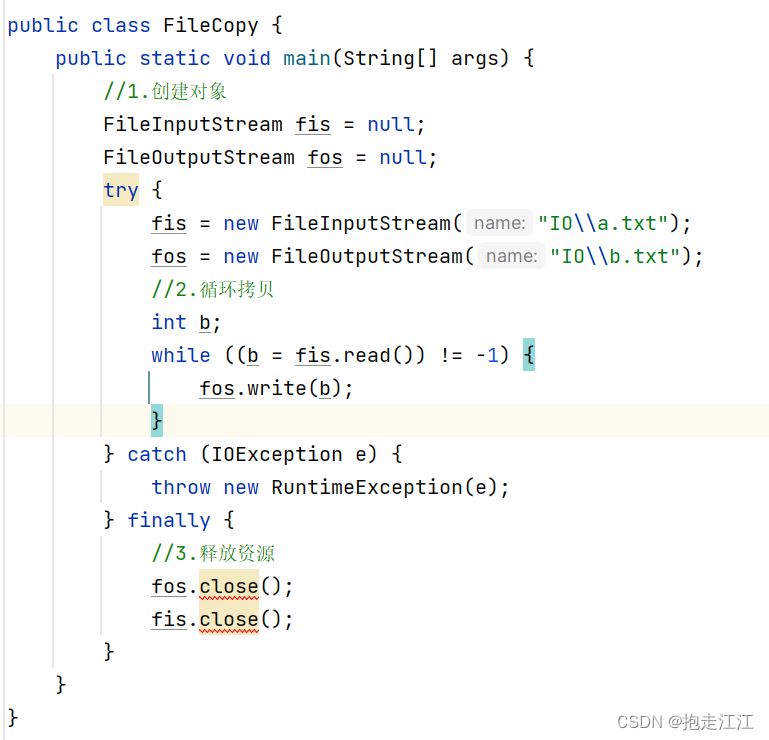
所以我们必须得将 fos 和 fis 定义在 try 外。
同时为了防止 fos 和 fis 未被初始化,还应初始化为 null 。
但由于 close 方法本身也会产生异常,所以针对 close 还需要捕获异常,也就是异常嵌套。
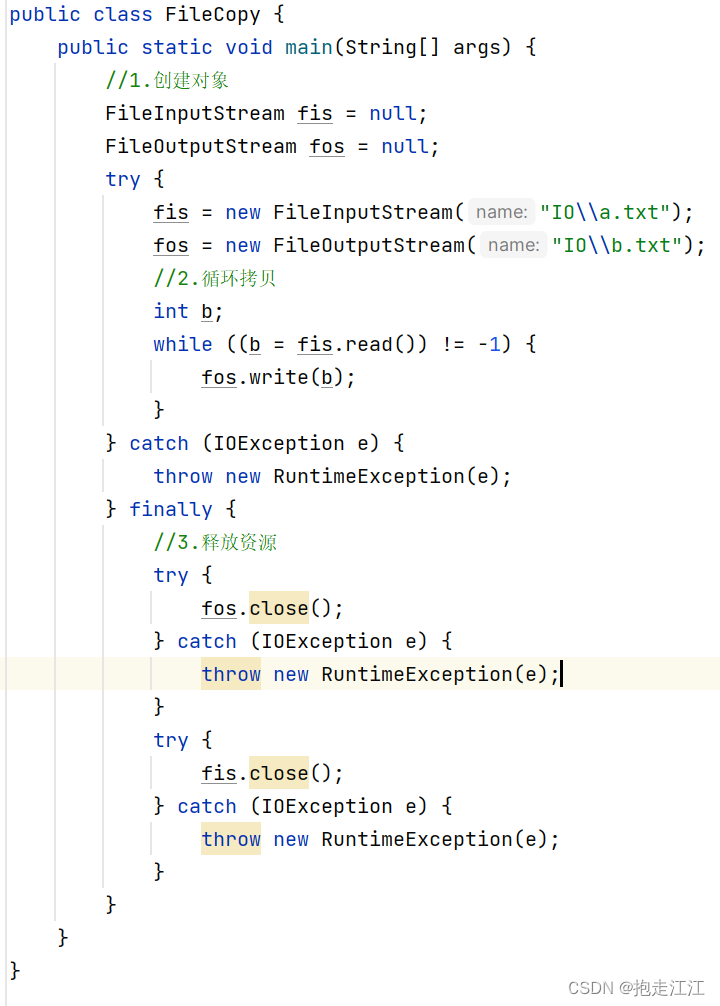
这时程序虽然没有编译时异常了,但仍存在一个问题:
如果 fos 创建对象时,父级路径不存在,就会创建失败。
同理 fis 创建对象时,路径不存在,也会创建失败。
此时 fos 和 fis 的值都仍是 null,如果在 finally 中调用 close 方法,就会产生空指针异常。
所以完整格式如下:
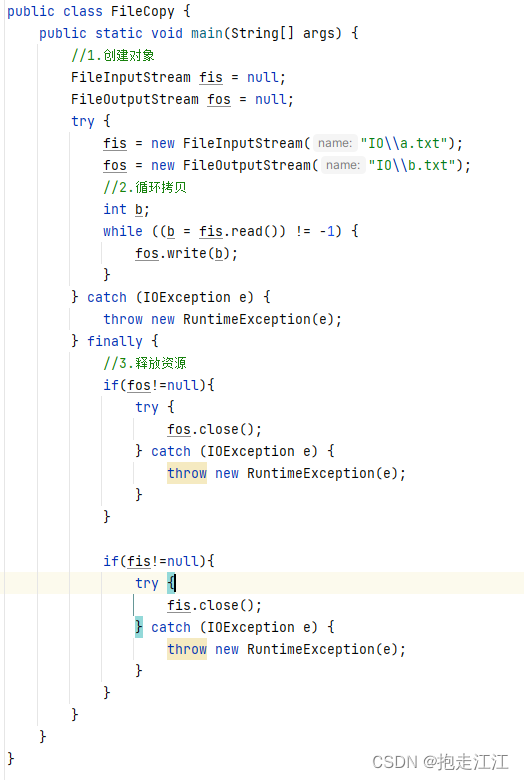
但这种书写方式太过麻烦,主要体现在资源释放上。
为此,java 提供了一个 AutoCloseable 接口:
凡是实现了该接口的,在特定的情况下,都可以自动释放资源,无需书写 close 代码。
(2)JDK7方案

注意:只有实现了 AutoCloseable 接口的类,才能在 try 的小括号中创建对象。
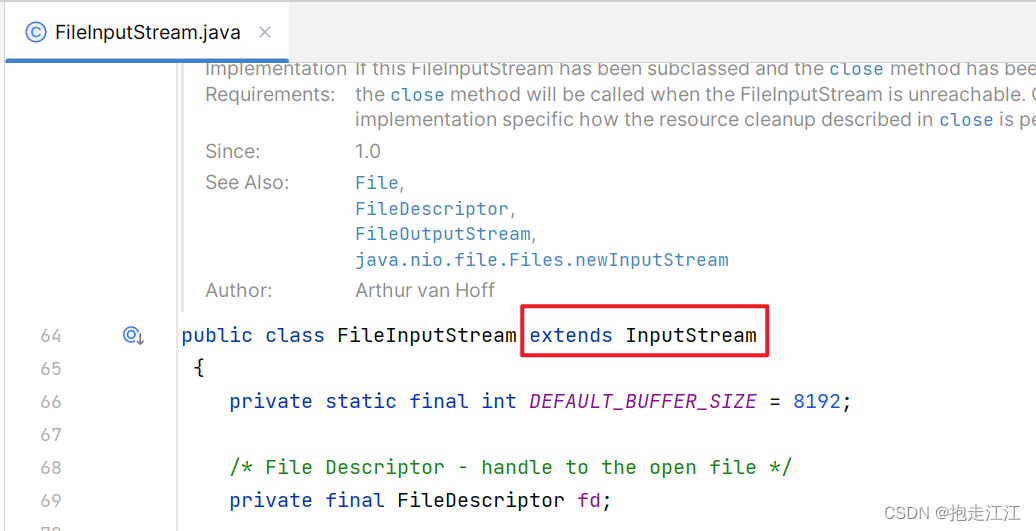
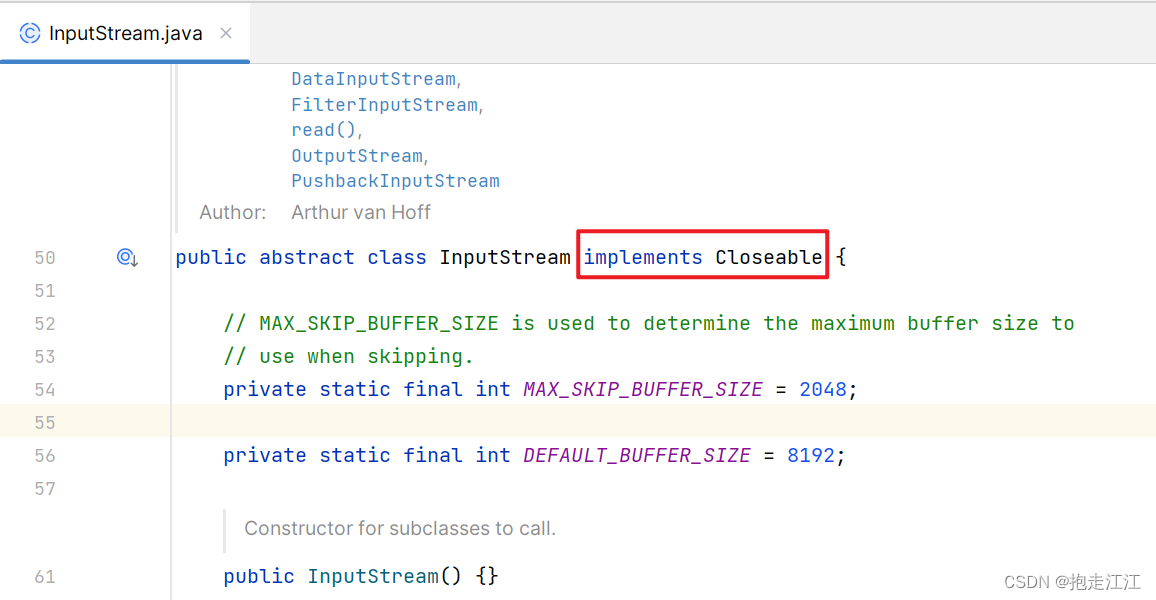

我们发现,FileInputStream 和 FileOutputStream 都间接实现了 AutoCloseable 接口。
所以,代码可修改为:
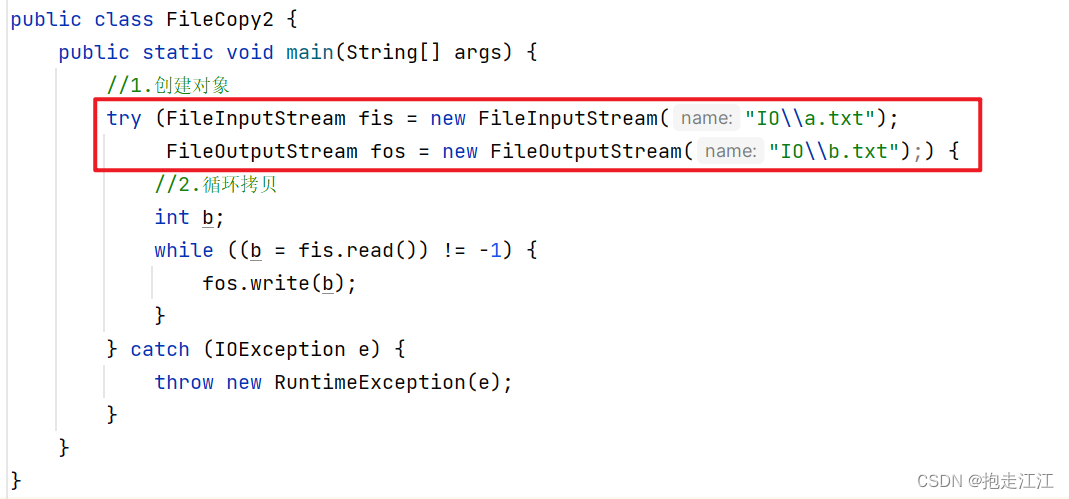
(3)JDK9方案
由于这样小括号中的可阅读性太差,JDK9 中又做了优化。

在 JDK9 开始后,创建对象的代码就可以放在外面写,try 的小括号里只需要写变量名即可。
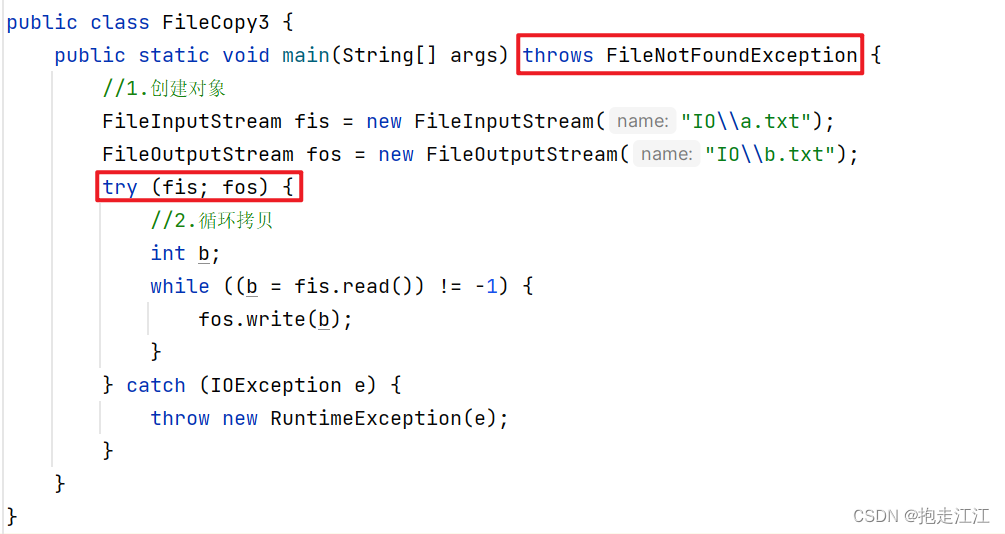
对于 fos 和 fis 创建对象时出现的异常,抛出处理即可。
三、字符集
在计算机中,任何数据都是以二进制的形式来存储的。
计算机中最小的存储单元是一个字节。
1.ASCII 字符集
在ASCII 码表中,总共制定了 2^7 = 128 种字符, ASCII 码从 0 到 127。
在 ASCII 字符集种,一个英文占一个字节。
一个字节 = 8 bit ,所以后面 7 个 bit 位用于表示不同的字符,即 2^7 = 128 种字符。
在编码时,高位补 0,所以第 1 位必定是 0。

2.GBK字符集
2000年3月17日发布,收录 21003 个汉字。
包含国家标准 GB130000-1 中的全部中日韩汉字,和 BIG5 编码(台湾地区繁体中文标准字符集)中的所有汉字。
注意:
① 简体中文版 windows 系统中默认使用的就是GBK。
② 在 GBK 字符集种,是完全兼容 ASCII 字符集的:
一个英文占一个字节,二进制第一位是 0 ;
一个中文占两个字节,二进制高位字节的第一位是 1(为了和ASCII 中的做区分)。


GBK 种,每个汉字由 2 个字节存储,2个字节 = 16 bit,也就是 2^16 = 65536 种。
由于要兼容ASCII 字符集,所以汉字的高位字节一定是以 1 开头,转成十进制之后也就是负数。
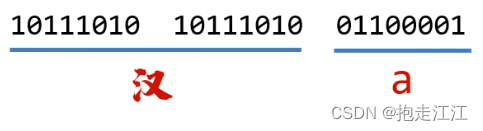
第一个字节的高位是 1,所以一定是中文汉字,看两个字节。
第三个字节的高位是 0,服从 ASCII 编码规范,是英文字符,所以看一个字节。
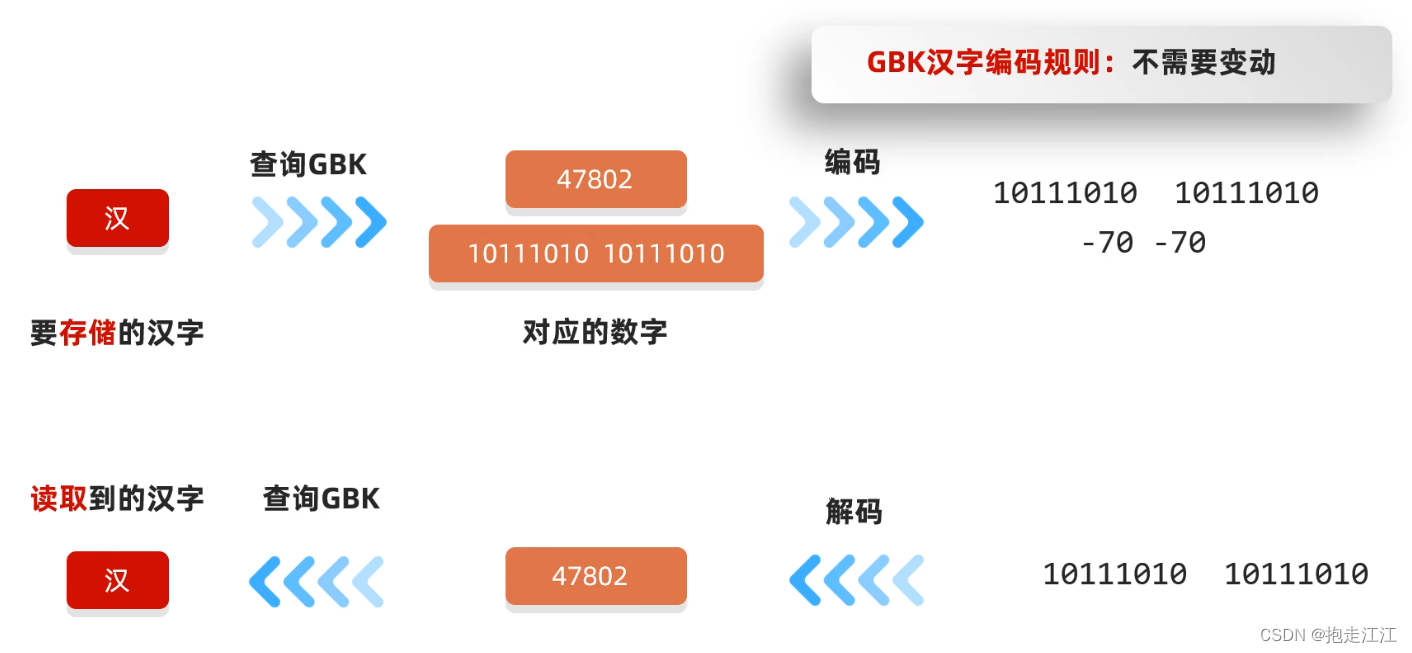
GBK在编码汉字时,不需要做任何变动。所以在解码汉字时,也不需要做任何变动。
3. Unicode字符集
Unicode :万国码(包含绝大多数国家的语言)
由统一码联盟(Unicode 组织)在1994年发布1.0版本,期间不断添加新的文字,最新版本是2022年9月3日发布的15.0版本。
Unicode 的三种编码方案
(1)UTF-16

规则:用 2 - 4个字节进行存储,高位全部补 0
(2)UTF-32

规则:固定采用 4 个字节进行存储,高位全部补 0
(3)UTF-8(最常用)
由于前两种编码方案都存在大量的补0,会造成内存空间的浪费,所以推出了 UTF-8。
规则:用 1 - 4个字节进行存储,英文占一个字节,中文占三个字节。

红色的表示固定格式,甚于部分再用字符的二进制进行填补,如:


4.乱码
原因1:读取数据时未读完整个汉字

对于 UTF-8编码的 "ai你哟",如果通过字节流的方式,每次读一个字节。
那么在读到第三个字节时,就是 11100100,转成十进制是 -28。
-28 在 ASCII 码表中对应的字符并不存在。在不同的操作系统中,就会显示 ?或者 □
原因2:编码和解码方式不统一

对于使用 UTF-8 方式进行编码的汉字,也应用 UTF-8 进行解码。
如果采用 GBK 方式进行解码,就会产生错误。

高位字节是 1,GBK 方式认为其是汉字,所以会读 2 个字节,十进制是 59057,-119。
在通过查找 GBK 字符集,获得 "姹"。
后面还有一个字节的数据,但也以 1 开头,所以 GBK 也会认为其是汉字,读取 2 个字节。
但字节数不够,就会乱码,显示 "�"。
5. Java 中的编码与解码

注意:在 IDEA编译器中,默认方式是 UTF-8;在 eclipse 编译器中,默认方式是 GBK。
public class Code {
public static void main(String[] args) throws UnsupportedEncodingException {
String str = "汉";
//1.编码
//1.1 使用默认方式进行编码
byte[] bytes1 = str.getBytes();
System.out.println(Arrays.toString(bytes1));//[-26, -79, -119]
//1.2 使用指定方式进行编码
byte[] bytes2 = str.getBytes("GBK");
System.out.println(Arrays.toString(bytes2));//[-70, -70]
//2.解码
//2.1 使用默认方式进行解码
String str1 = new String(bytes1);
System.out.println(str1);//汉
//2.2 使用指定方式进行编码
String str2 = new String(bytes1,"GBK");//编码和解码方式不一致:乱码
System.out.println(str2);//姹�
String str3 = new String(bytes2,"GBK");
System.out.println(str3);//汉
}
}
四、字符流(以操作本地文件为例)
由上可知,乱码的原因有两个,编码和解码方式统一这个很好实现。
所以,主要原因在于读取数据不完整,如何解决?

字符流的底层其实就是字节流 ,只不过在字节流的基础上又添加了字符集。
特点:
输入流:一次读一个字节,如果遇到中文,一次读多个字节。
输出流:底层会把数据按照指定的编码方式进行编码,变成字节在写到文件中。
使用场景:对于纯文本文件进行读写操作。
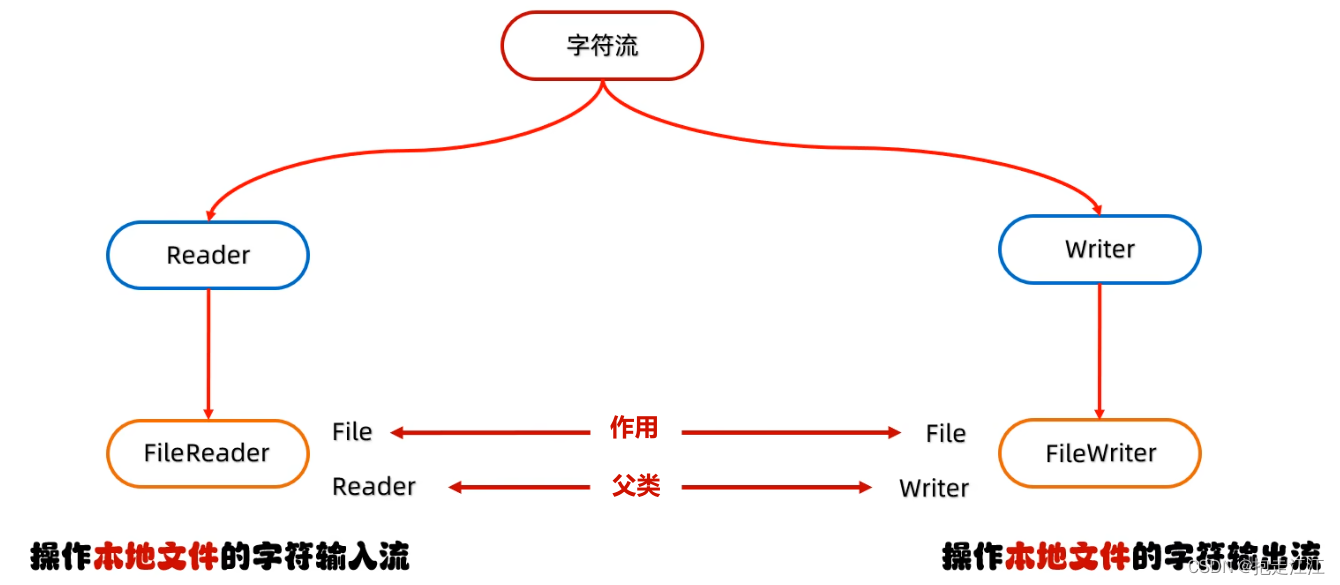
1. FileReader 类
(1)定义
步骤:
① 创建字符输入流对象
② 读取数据

③ 释放资源

(2)读数据的两种方式
Ⅰ. 空参 read 方法
细节:
① 虽然字符流的 read 和 write 方法的操作单位都是一个字符,但本质上:
字符流的底层也是字节流,默认是一个一个字节读取的。
但如果遇到中文就会一次读取多个, GBK 一次读两个字节,UTF-8一次读三个字节。
② read 方法在读取之后,方法底层还会进行解码并转成十进制,最终将这个十进制作为返回值。
英文:a --> 文件中的数据:0110 0001 --> read 方法进行读取,解码并转成十进制:97
中文:汉 --> 文件中的数据:11100110 10110001 10001001 --> read 方法进行读取,解码并转成十进制:22721
所以,需要使用强制转换,将十进制数转换为字符型。

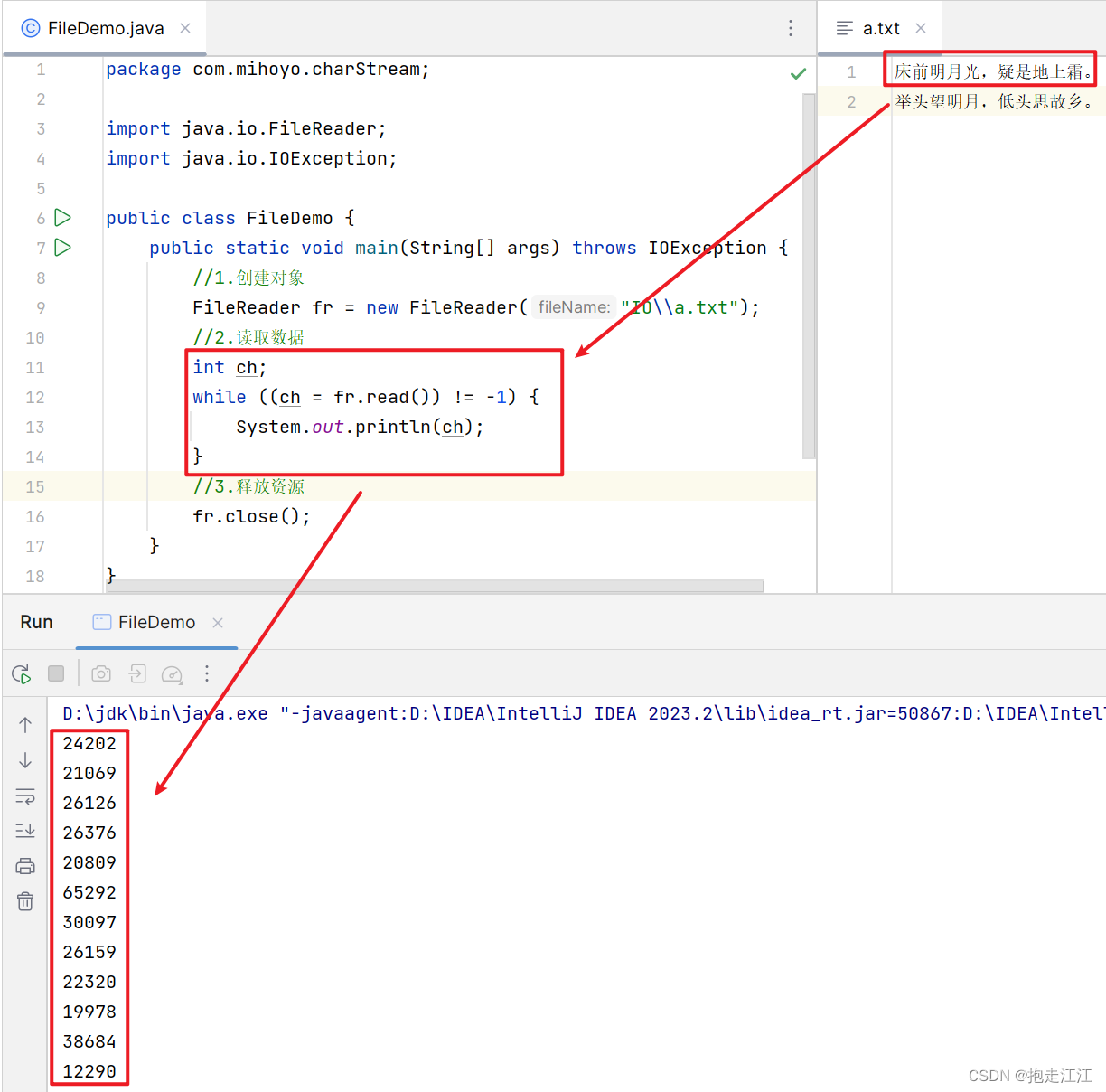
Ⅱ. 有参 read 方法
细节:
read(char[] buffer):读取数据,解码,强转 三步合并在一起,把强转之后的字符放到数组中。
即:有参的 rea的方法,相当于 空参的 read 方法 + 强制类型转换。
(3)底层原理
① 创建字符输入流对象:
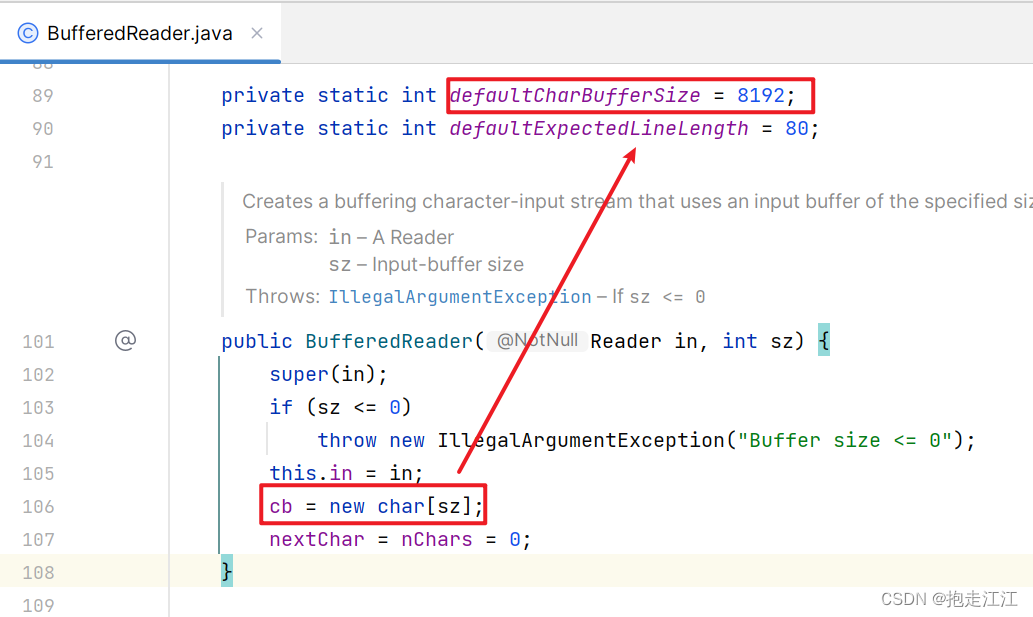
底层:关联文件,并创建缓冲区(长度为8192的字节数组,默认初始化 0)。
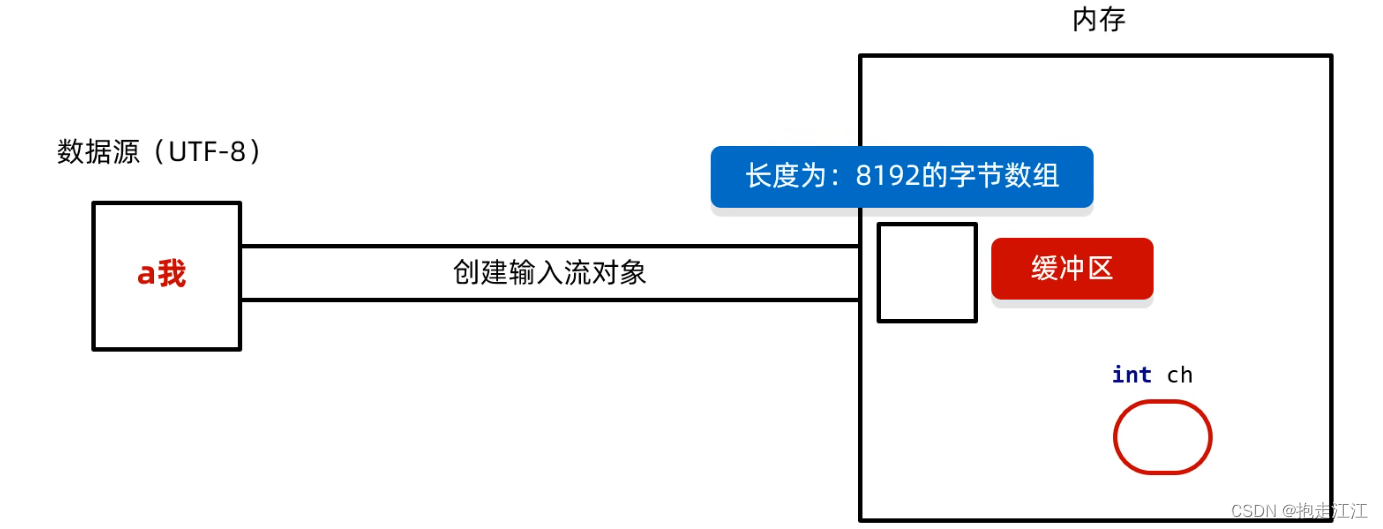
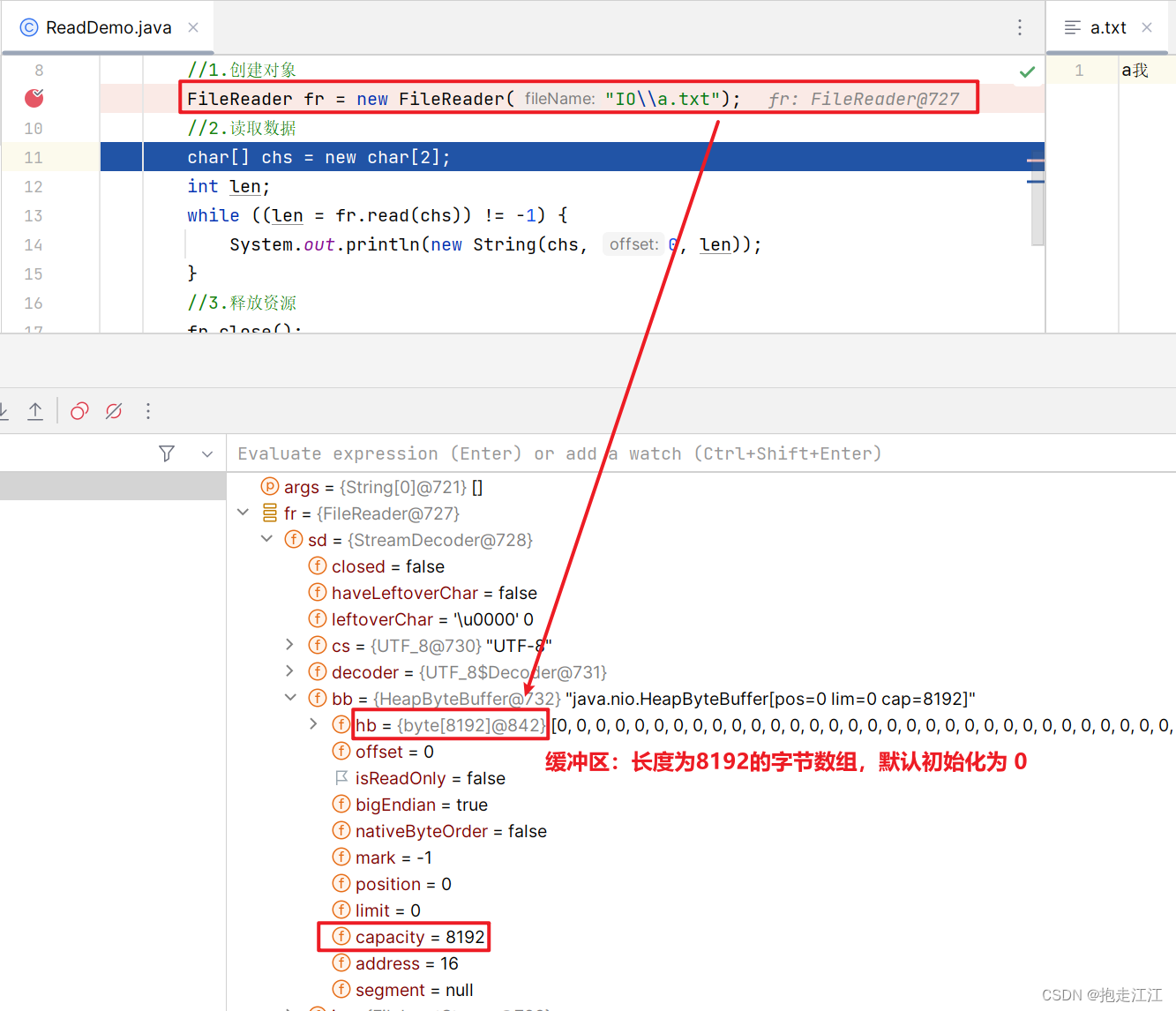
② 读取数据
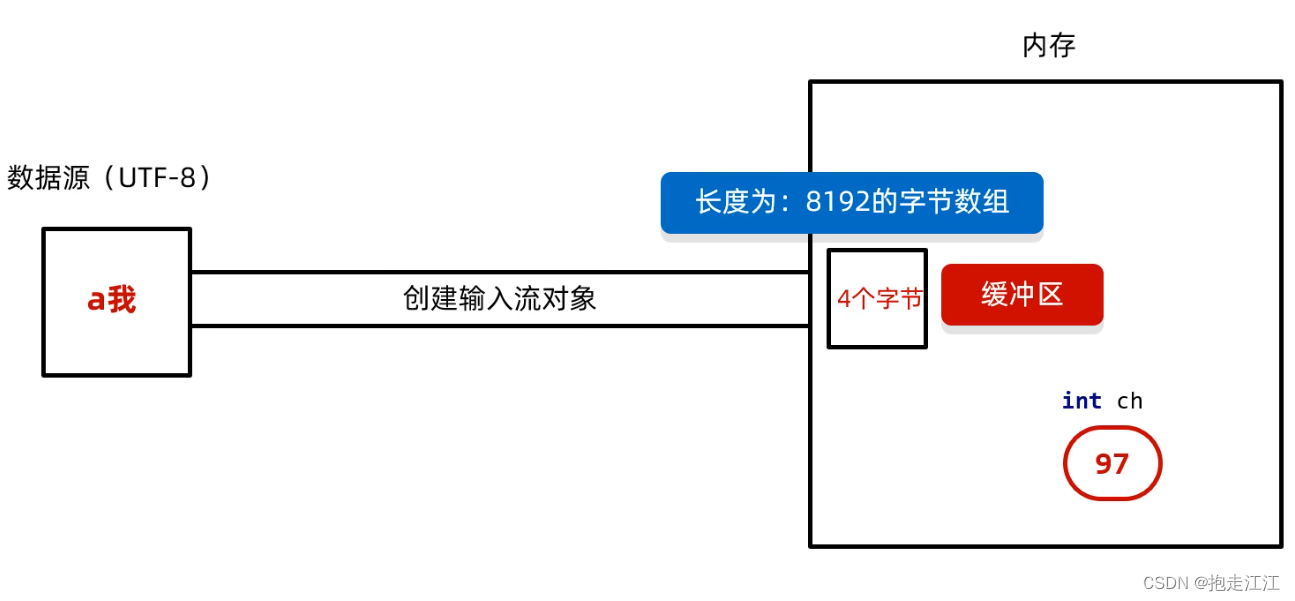
底层:判断缓冲区中是否有数据可以读
Ⅰ. 缓冲区中没有数据:就从文件中获取数据,装到缓冲区中,每次尽可能装满缓冲区
如果文件中也没有未获取的数据了,就返回 -1。
Ⅱ. 缓冲区中有数据:就从缓冲区中读取 (等缓冲区中全部读完,再次去文件中获取数据装入)
空参的 read 方法:一次读一个字节,遇到中文一次读多个,把字节解码后转成十进制返回
有参的 read 方法:把读取字节,解码,强转三步合并了,强转之后的字符放到字符数组中
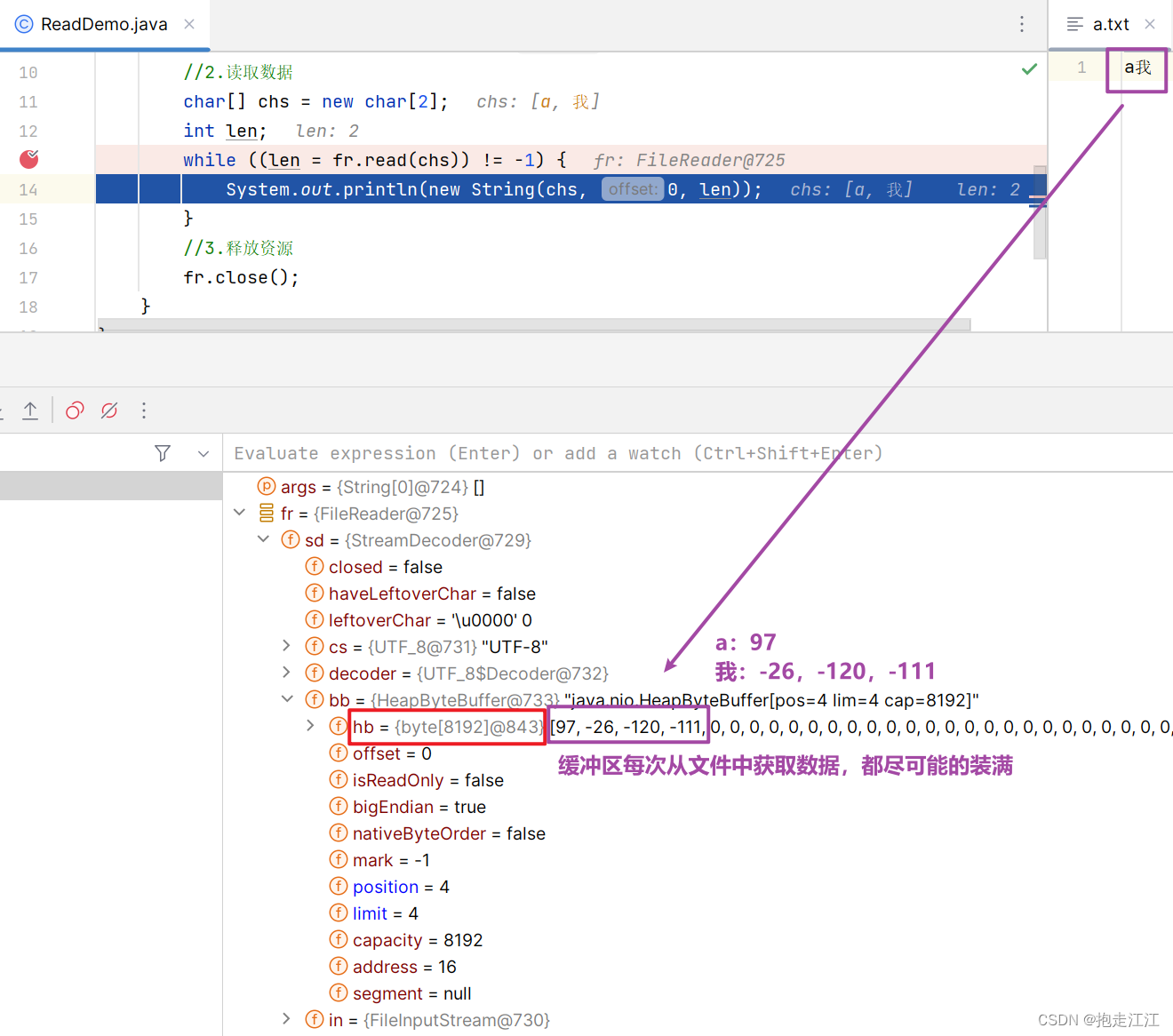
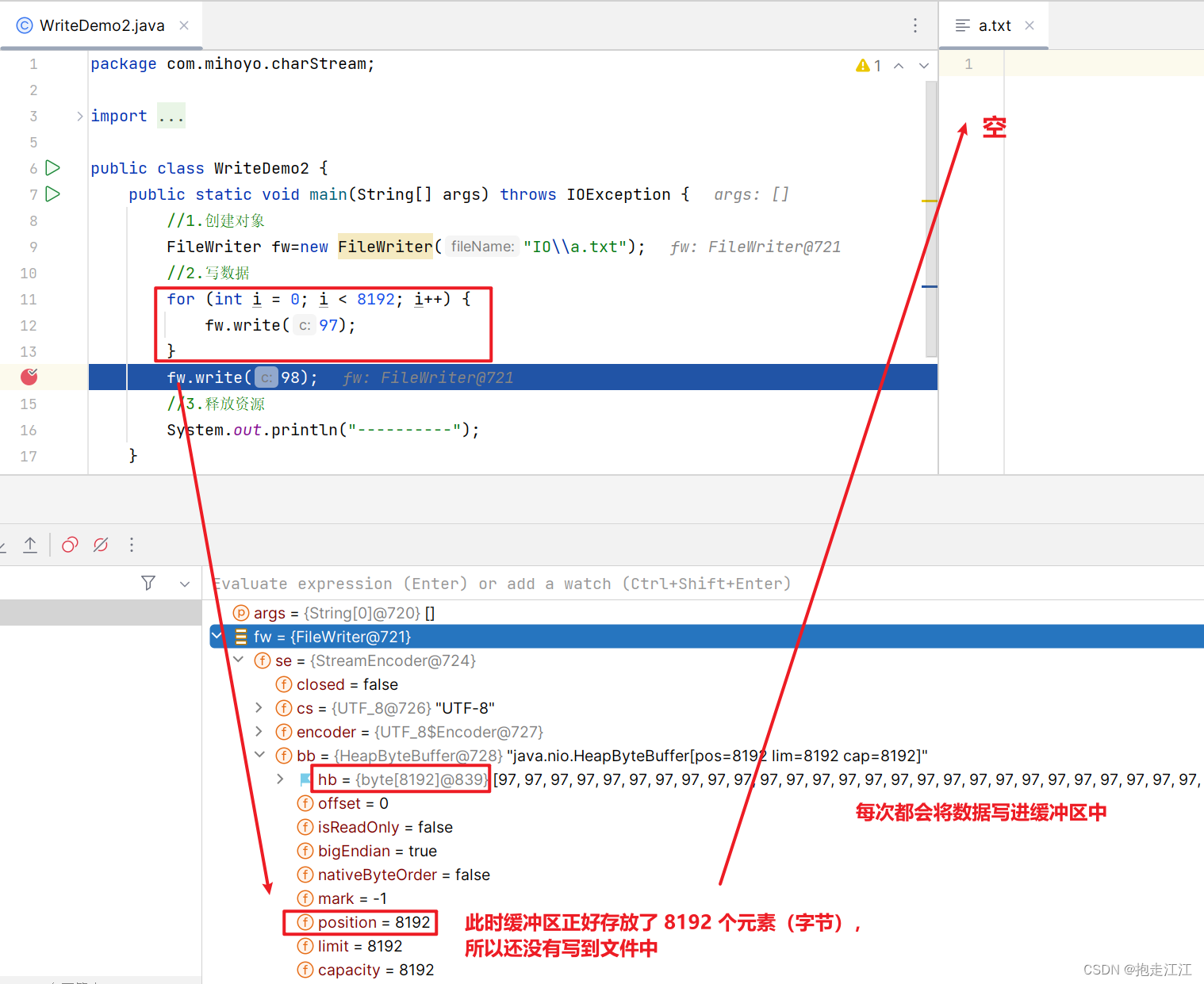
Test:我们知道,输出流对象 fw 一旦创建,就会清空文件中的数据。针对以下代码,fr 是否能读取到数据呢?
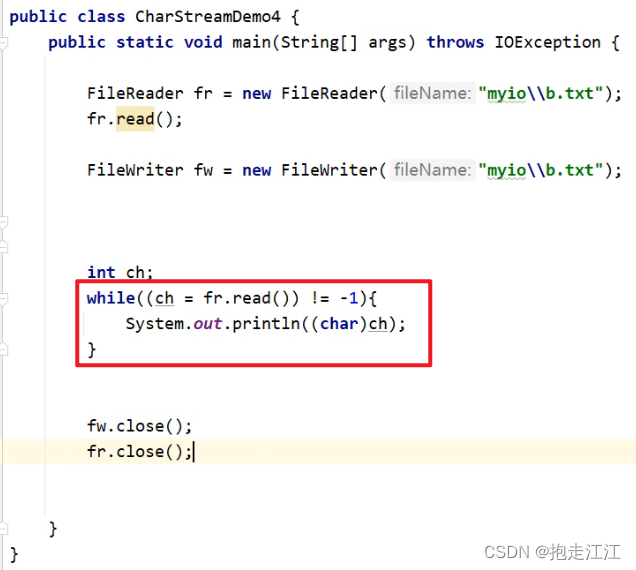
答案是可以的,但最多只能读到前 8192个字节的数据,文件中剩余的数据是无法读取到的。
因为 fr 先调用 read 方法进行读取,它会将文件中的数据尽可能装满缓冲区(最多8192个字节)。
之后 fw 对象创建,这时才会立即清空文件中的数据。
所以之后 read 方法继续读取时,fr 中的缓冲区仍存在数据,可以读取。
但一旦缓冲区中数据全部读完,再次去文件中获取未读取的数据时,就获取不到了。
原则:IO 流随用随创建,不用则关闭。(为了防止提前创建 fw 而清空文件数据)
2. FileWriter 类
(1)定义
步骤:
① 创建字符输出流对象

② 写数据

③ 释放资源
(2)写数据的五种方式
这里只演示其中三种,剩余两种和上面类似,不在过多介绍。
I. write(int c)
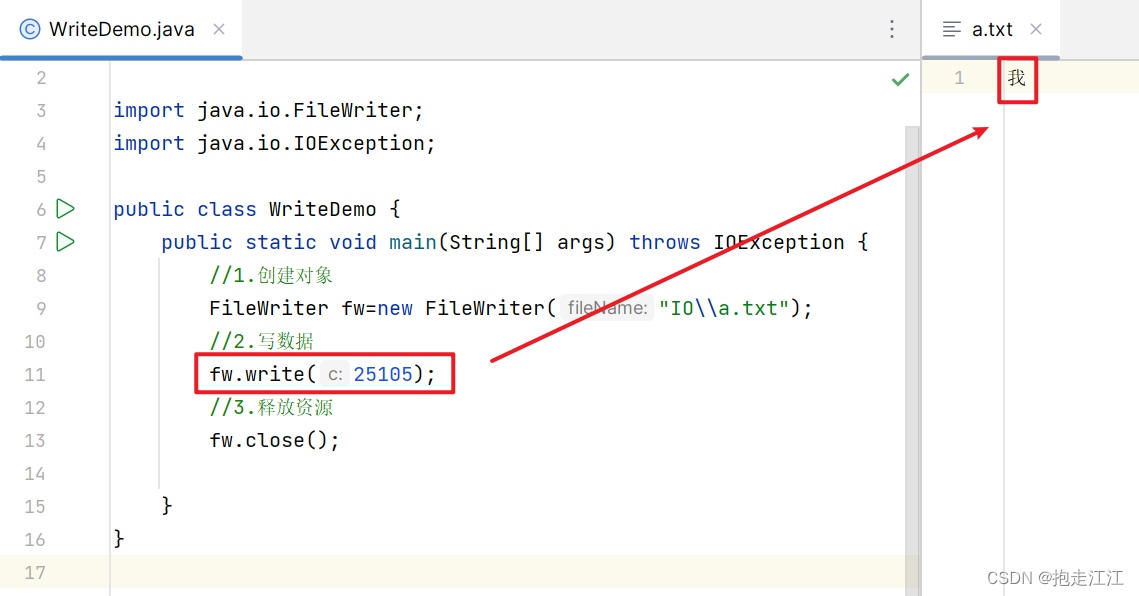
细节:
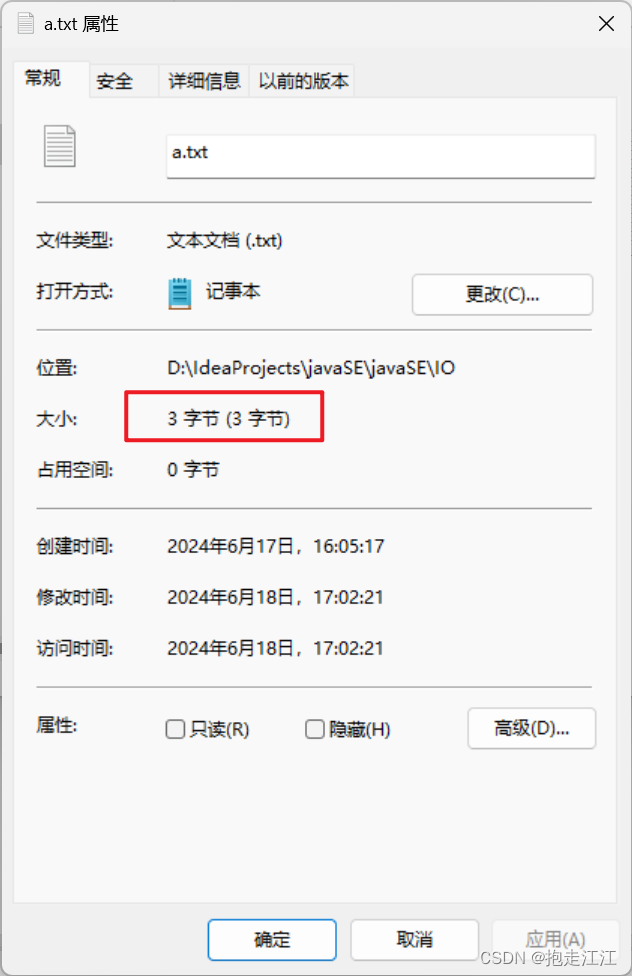
write 方法会在底层根据字符集的编码方式进行编码,把编码之后的字节数据写到文件中去。
IDEA 的默认编码方式是 UTF-8,所以编码后的这个汉字应该占 3个字节。
Ⅱ. write(string str) 最常用
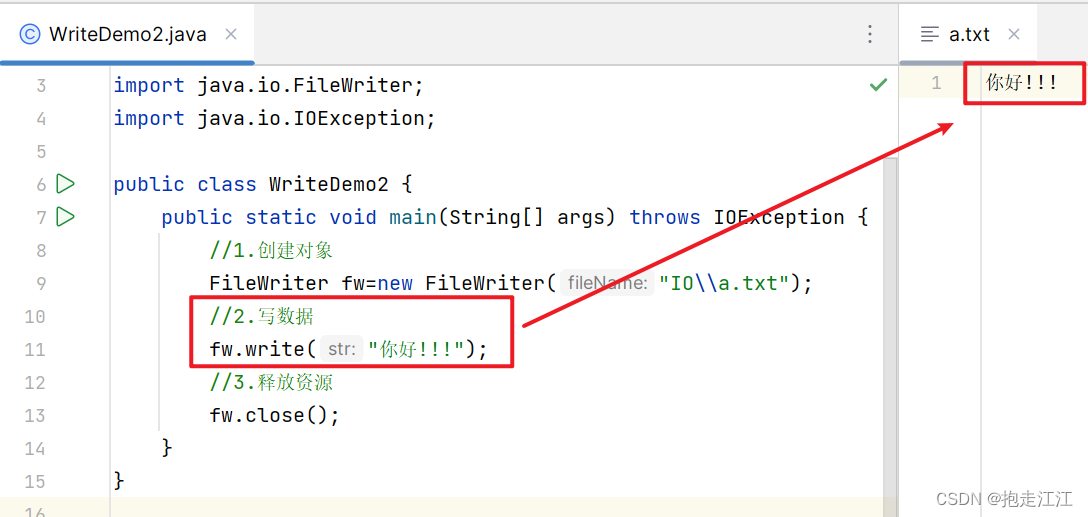
细节:
方法的底层也会根据当前的编码方式和码表进行编码,将对应的字节数据写到文件中去。
“你好” 一共占 2*3=6个字节,三个感叹号是英文状态下的,所以占 3*1=3 个字节,一共占 9 个字节。
Ⅲ. write(char[] cbuf)
注:如果想要续写,构造方法中 append 参数传递为 true 即可。
(3)底层原理
① 创建字符输出流对象:
底层:关联文件,并创建缓冲区(长度为8192的字节数组,默认初始化 0)。
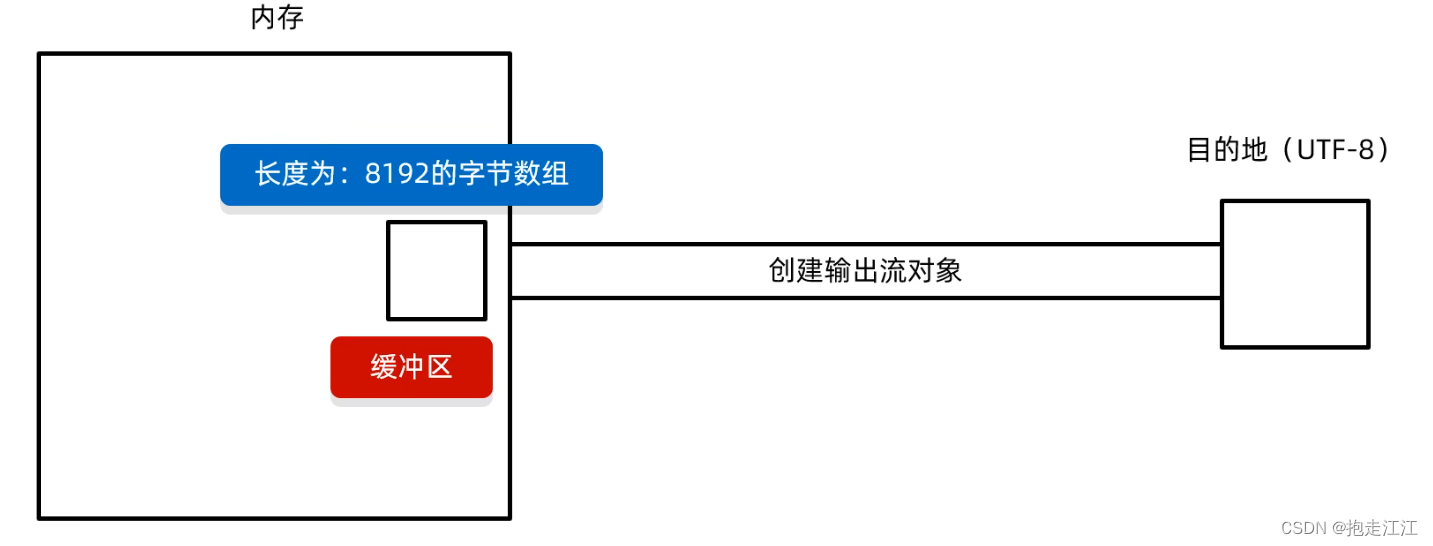

注意:fr 和 fw 的缓冲区不是同一个缓冲区,都有各自对应缓冲区(字节数组)
② 写出数据
底层:会将数据都写到缓冲区中
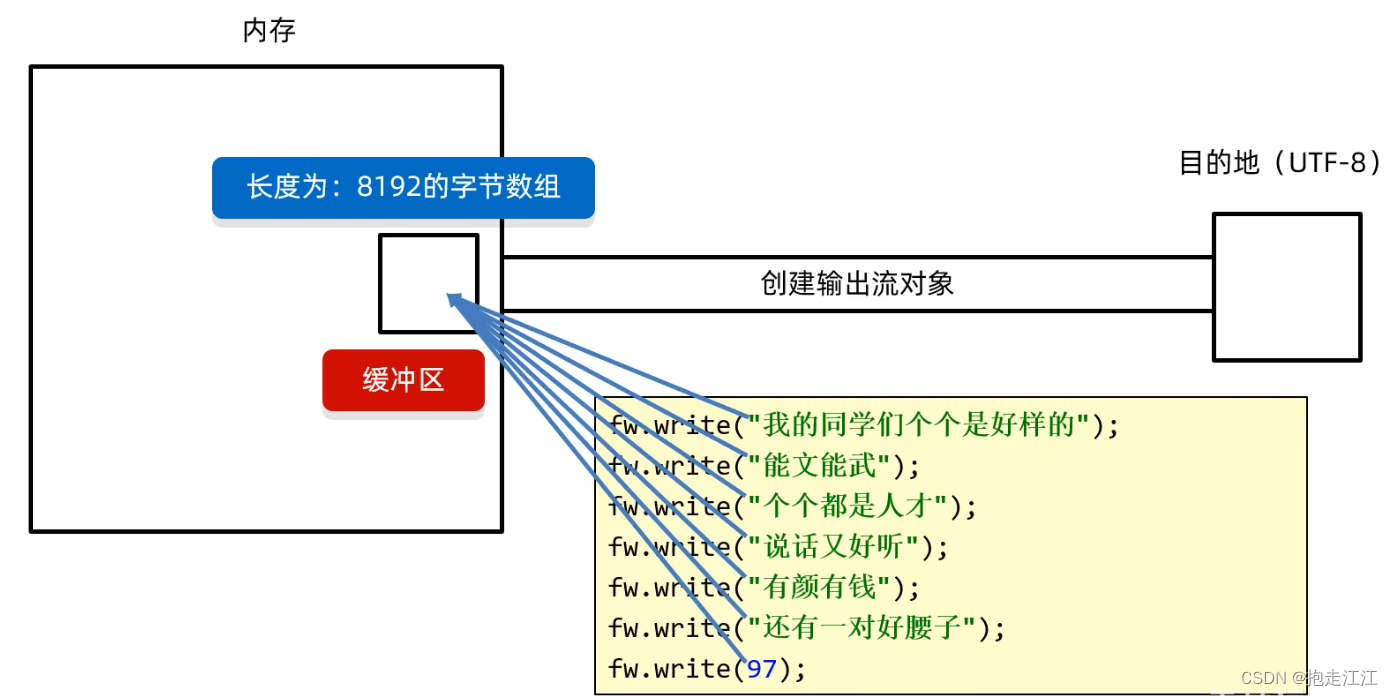
当以下三种情况发生时,会将缓冲区中的数据全部写进目标文件中:
Ⅰ. 往缓冲区中添加数据,发现缓冲区已经满了时
Ⅱ. 调用 flush 方法手动刷新
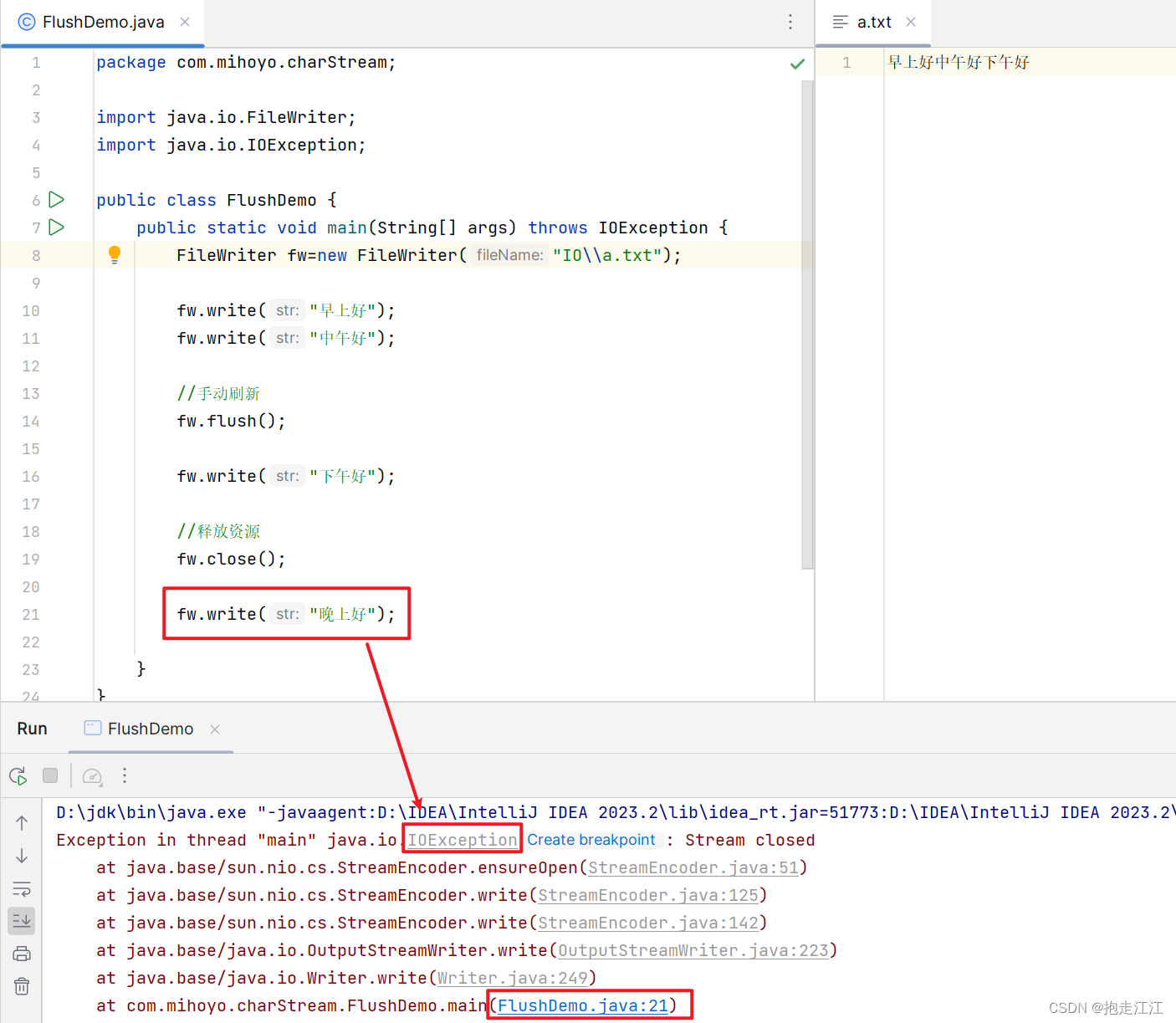
Ⅲ. 调用 close 方法释放资源


flush 和 close 的区别 :
flush 刷新:刷新之后,还可以继续往文件中写出数据。
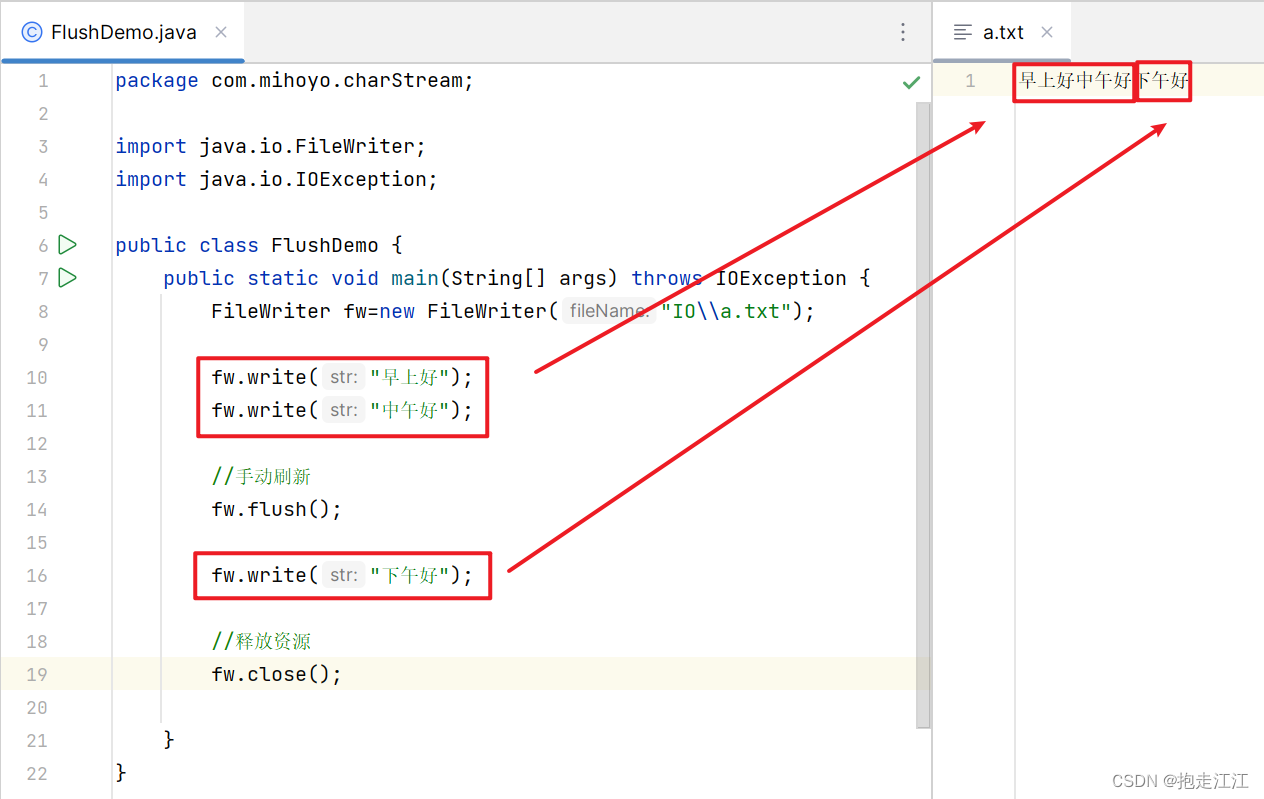
close 关流:断开通道,无法再往文件中写出数据(如果继续写,则报错) 。
五、缓冲流
1.定义

缓冲流:就是在基本流的基础之上进行包装,增加了缓冲区 ,用来提高读写的效率。
(由于 FileReader 和 FileWriter 已经有缓冲区,所以提升并不明显,但包装后提供了很多新的方法)
2.字节缓冲流
(1)使用

原理:底层自带了长度为 8192 的 缓冲区提高性能
public class CopyDemo {
public static void main(String[] args) throws IOException {
//1.创建缓冲流对象
BufferedInputStream bis = new BufferedInputStream(new FileInputStream(("IO\\a.txt")));
BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream("IO\\b.txt"));
//2.循环读取并写出数据
int b;
while ((b=bis.read())!=-1){
bos.write(b);
}
//3.释放资源
bos.close();
bis.close();
}
}
Question1:增加的缓冲区在哪里呢?
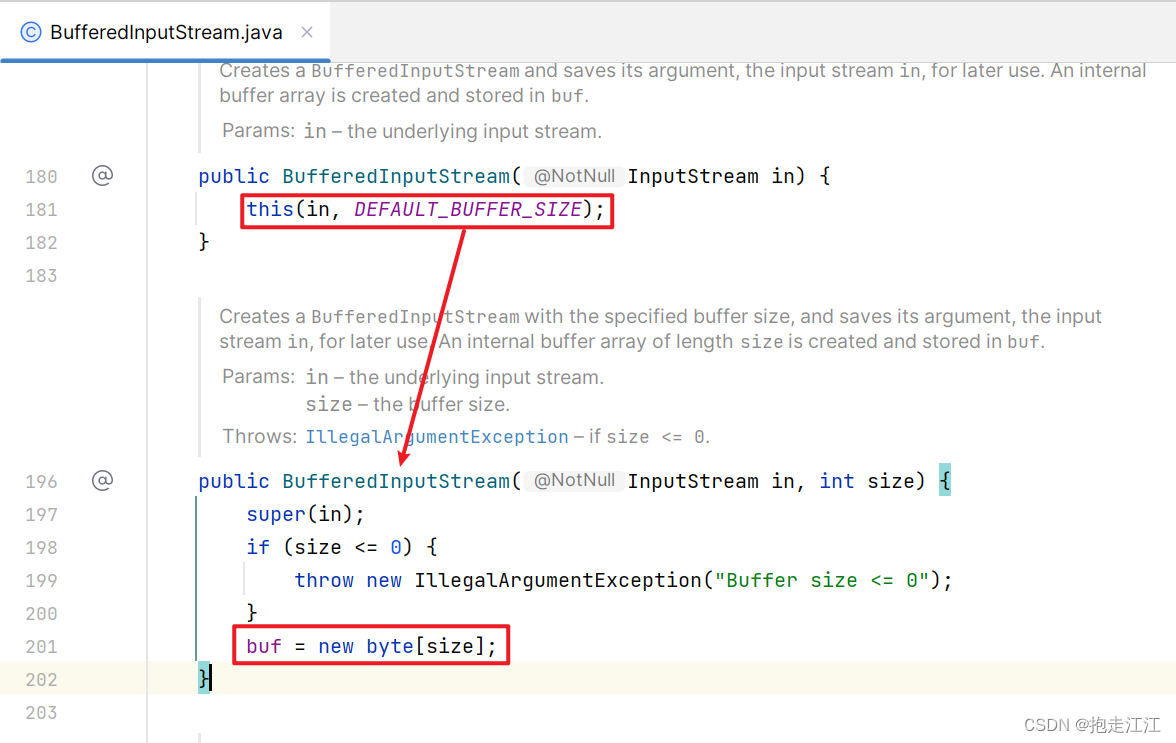
BufferedInputStream 调用构造方法时,底层创建了一个大小为 DEFAULT_BUFFER_SIZE 的字节数组。
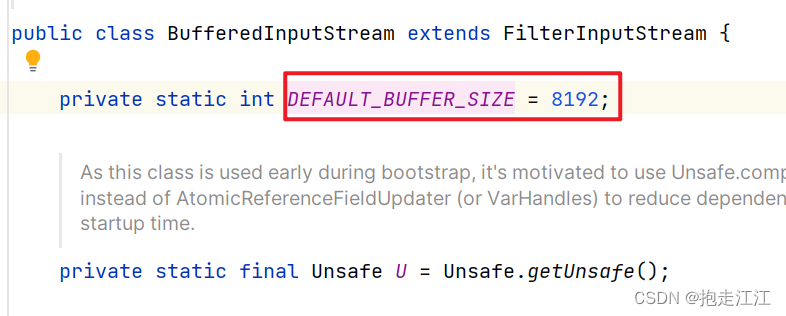
而这个 DEFAULT_BUFFER_SIZE 的值为 8192。
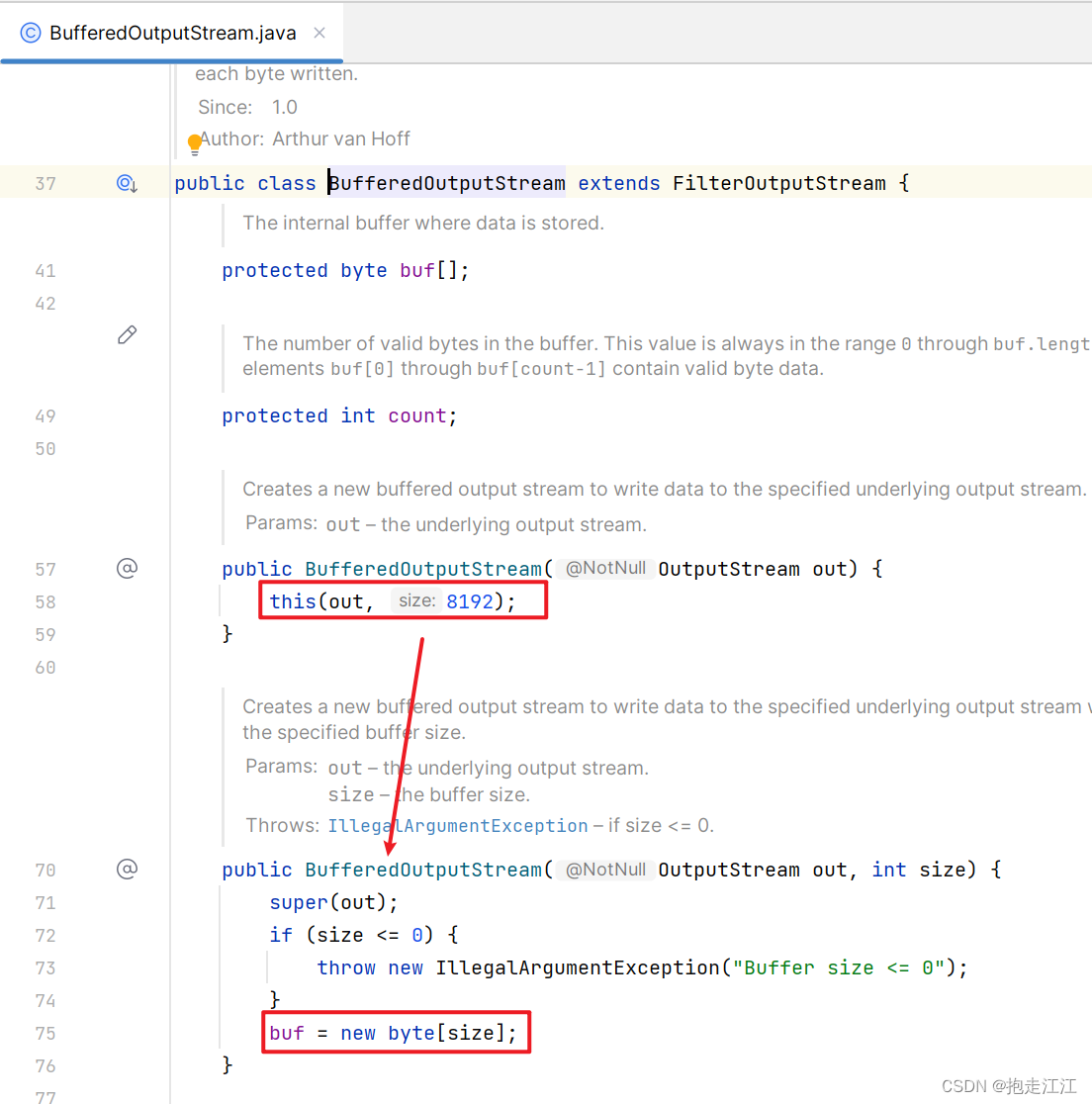
BufferedOutputStream 在调用构造方法时,也会创建一个长度为 8192 的字节数组(缓冲区)。
Question2:为什么关流的时候,不需要关基本流呢?
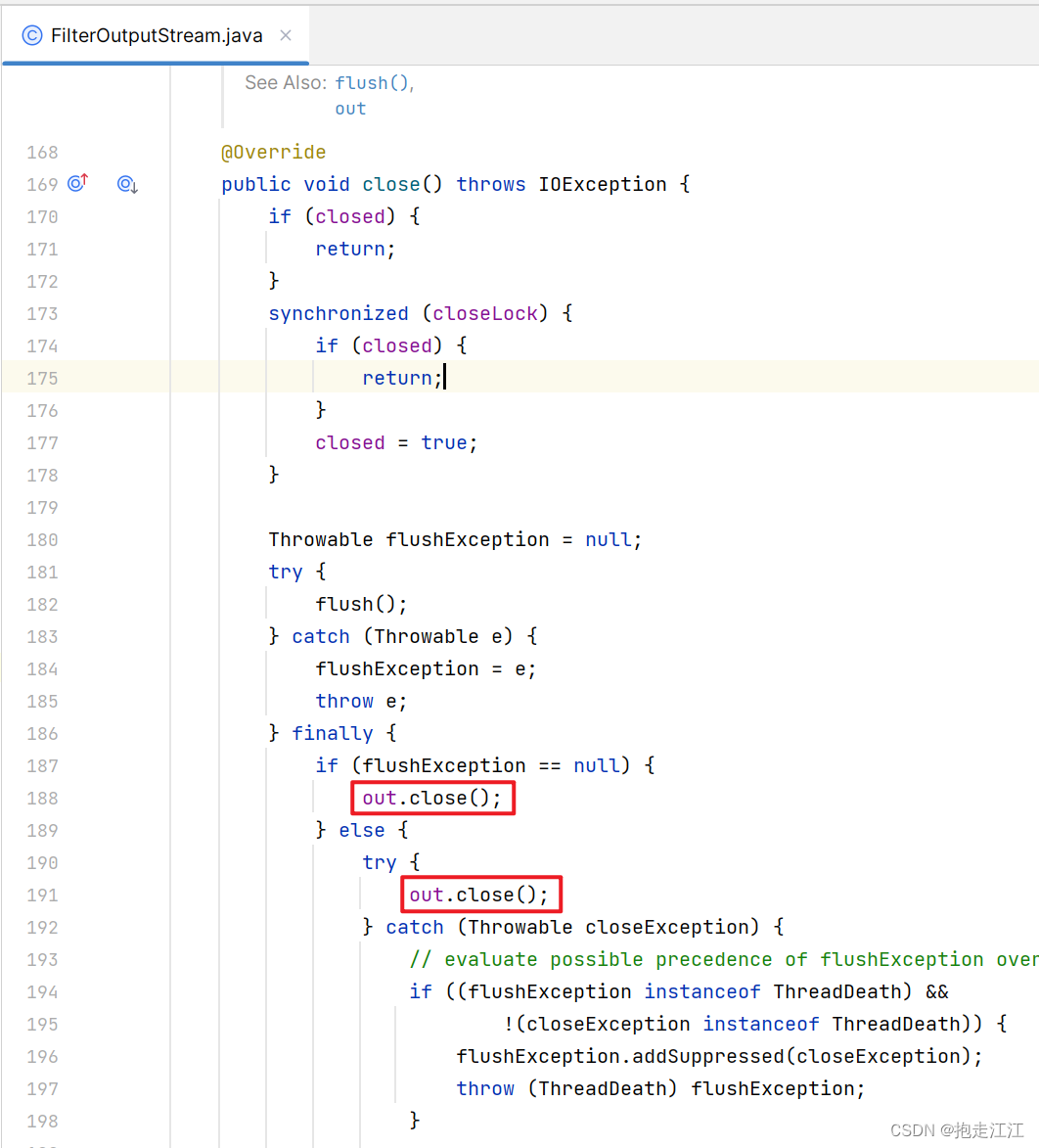
在 close 方法中,其实也将基本输出流进行了关闭。
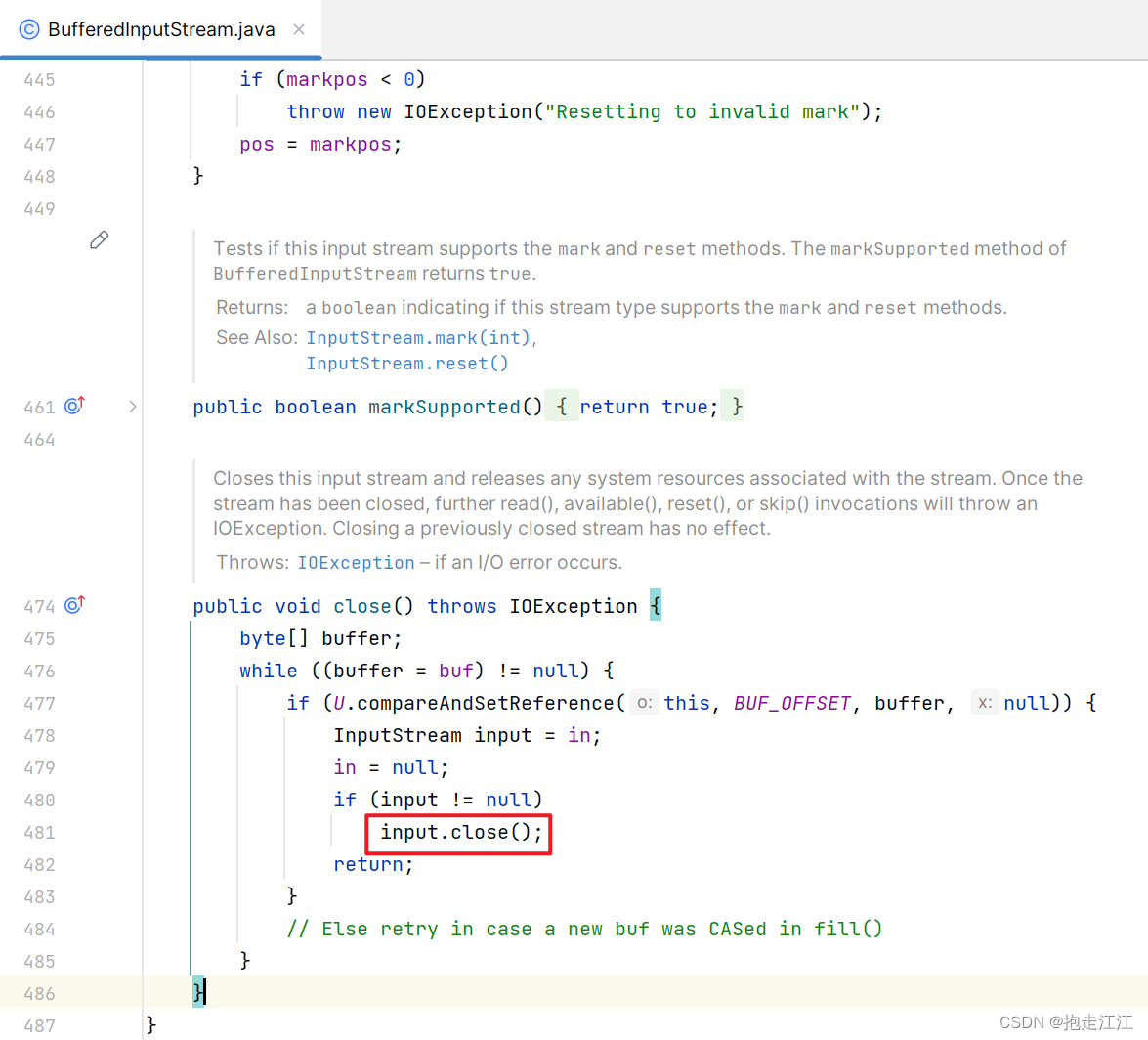
同理,在 close 方法中,也将基本输入流进行了关闭。
(2)底层原理
① 首先基本流会从硬盘中的文件中读取数据,将数据放进缓冲区当中,一次性会读 8192 个字节的数据。
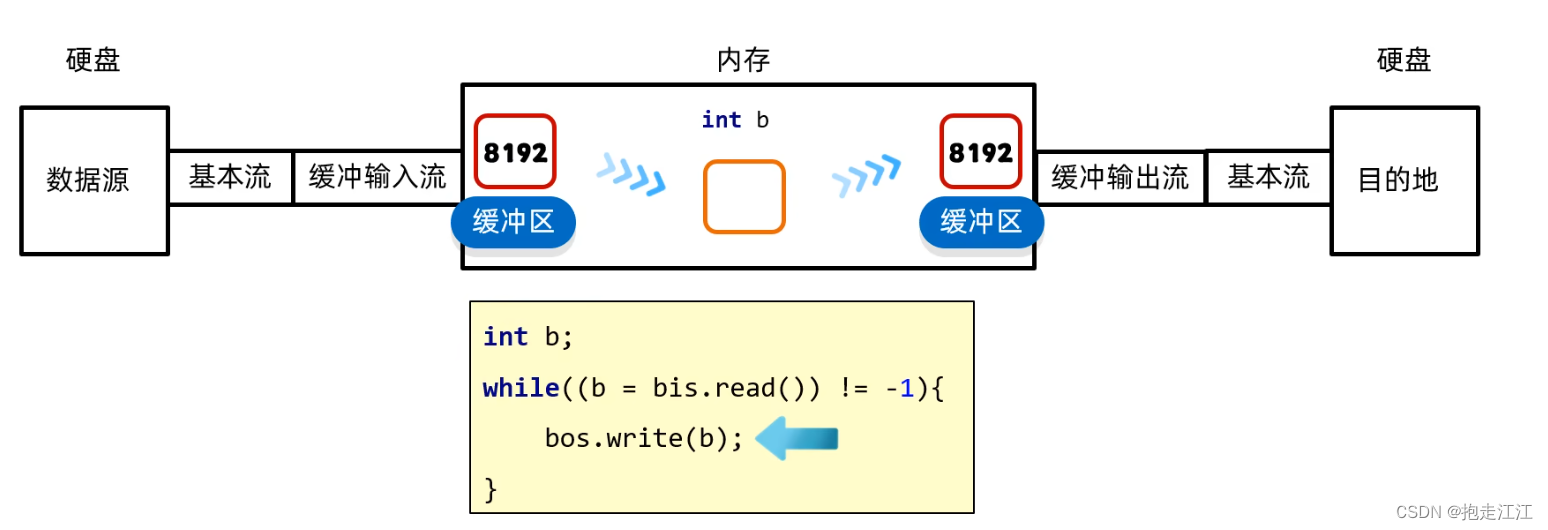
② 再通过变量 b 从输入缓冲区中拿数据,写到数据输出缓冲区中。
③ 当输出缓冲区已经满了时,会将缓冲区中的数据通过基本流一次性写到文件中去。
注意:
① 虽然这种方式也是一个一个字节从输入缓冲区传到输出缓冲区中,但这个操作是在内存中进行的。
在内存中的运算速度是非常快的,可以忽略不计。
真正节约的是读和写的时候,跟硬盘之间操作的时间。
② read 方法和 write 方法都是对缓冲区进行读取和写出的,真正对文件进行操作的还是基本流。
③ 从硬盘中读取数据到缓冲区中,和 FileReader 一样,也是在调用 read 方法时进行的。
从缓冲区中写出数据到硬盘中,和 FileWriter 一样,也是在装满,flush,close三种情况时发生的
④ 如果是有参的 read 方法,区别仅仅是:每次对缓冲区进行读写数据,不是一个一个字节,而是一次一个数组的大小。--> 只是中间的内存中的运算过程更快而已。
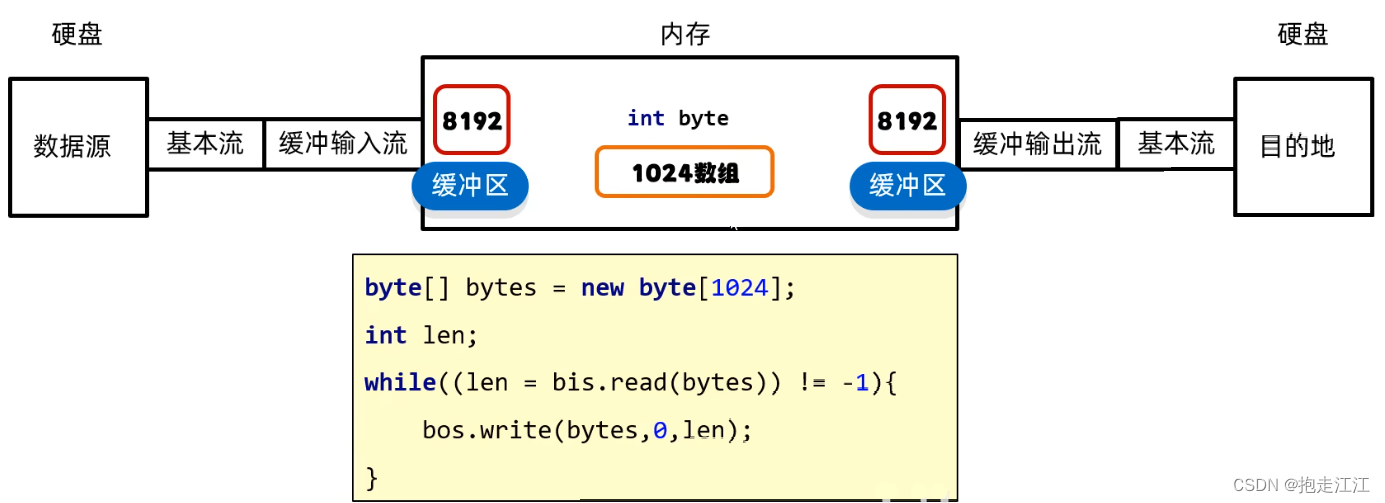
3.字符缓冲流

原理:底层自带了长度为 8192 的缓冲区提高性能。
由于字符基本流中已经存在缓冲区,所以提升效果不大,但包装后提供了很多特有的方法。

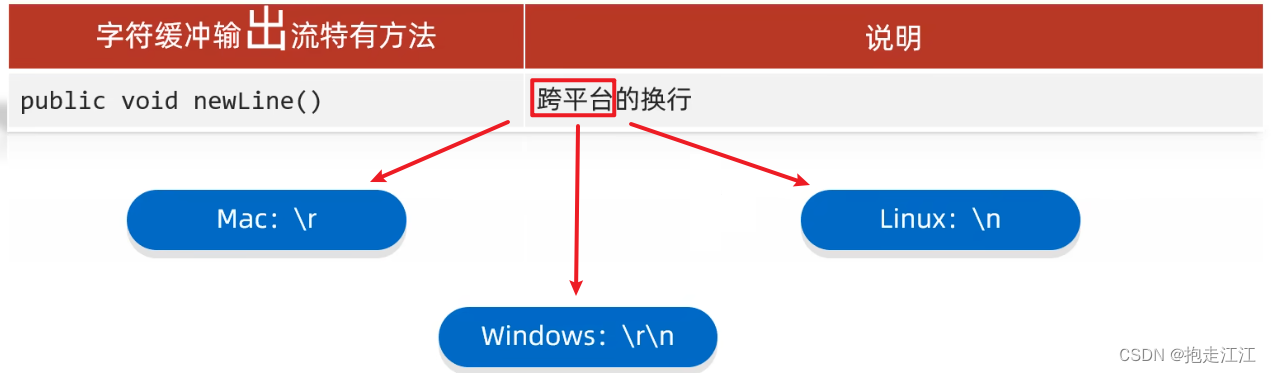
细节:
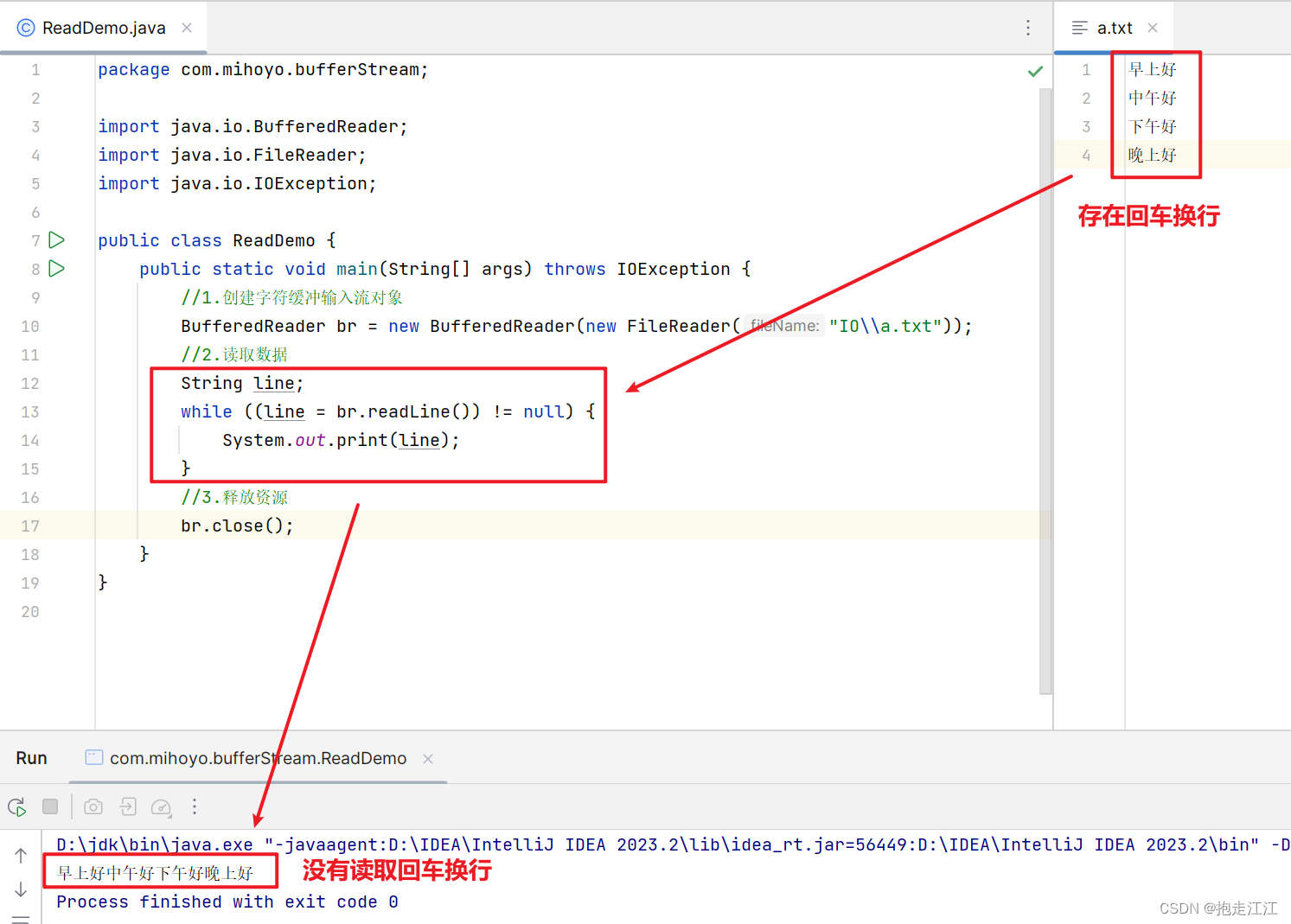
① readLine 方法在读数据时,一次读一整行。
在缓冲区中遇到回车换行符结束,但不会把回车换行读到内存中。
② readLine 方法在读到文件末尾时,不会返回 -1,而是返回 null。
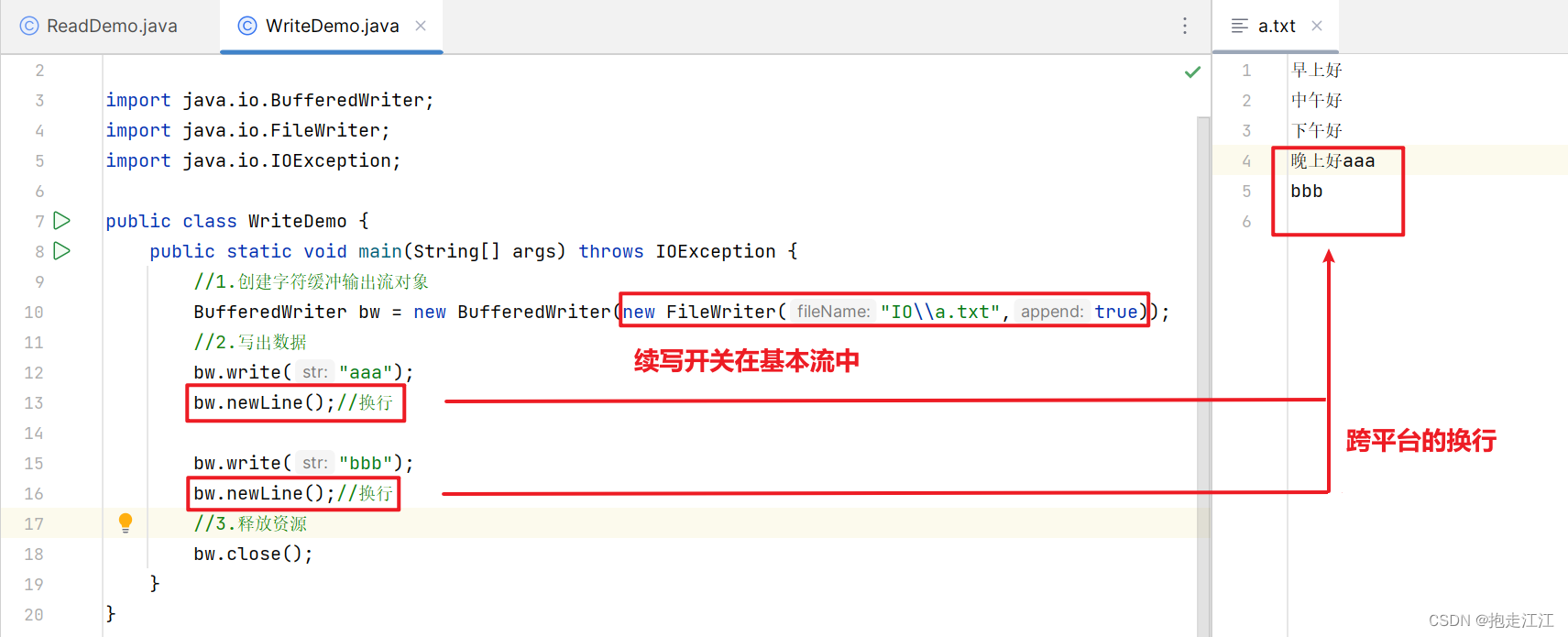
③ 以上所有的构造方法,续写:append 参数都是在基本流的构造方法中,而不是在高级流中。
④ 在字节缓冲流中,底层的缓冲区是 8192 的字节数组,即 8 KB。
而在字符缓冲流中,底层的缓冲区是 8192 的字符数组,即 16 KB。
(在 Java 中,1 个字符 = 2 个字节)
六、转换流
1.引言
前面说过,IDEA 默认的编码方式是 UTF-8,所以无论是在读取还是写出数据时,都是用 UTF-8 方式进行编码和解码的。
Question:如果现在有一个 GBK 的文件,想要成功读取其中的数据,如何实现?
可以通过字节流进行读取,然后对字节通过 GBK 方式进行解码
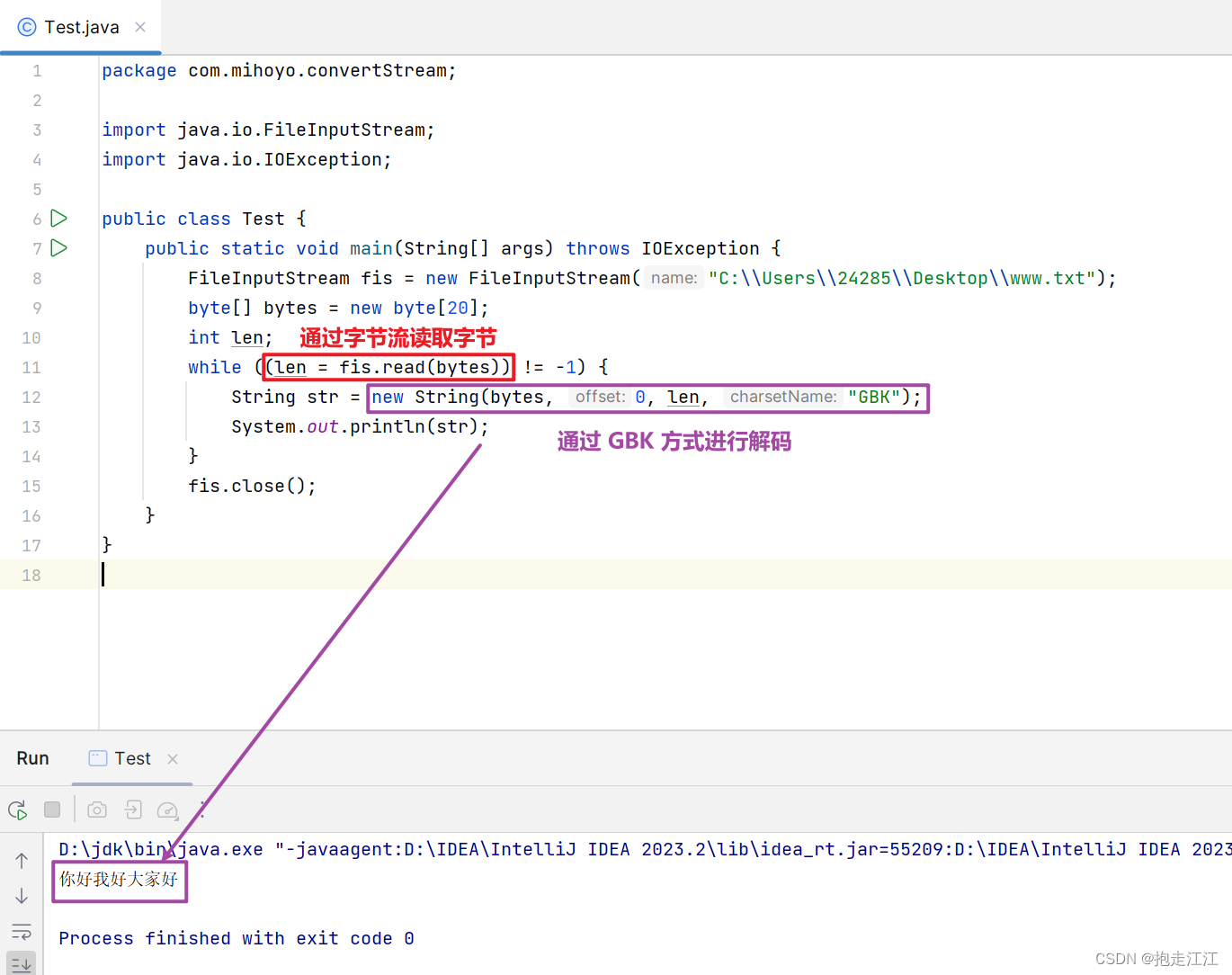
但有一个缺点,字节数组的大小是不确定的。
当数组的字节数 >= 文件中数据的字节数,结果是正常的。
如果数组的字节数 < 文件中数据的字节数,就有可能发生问题。
比如,文件中的数据 "你好我好大家好" 是GBK 方式编码的,所以共占 2*7=14个字节。
如果数组长度小于 14个字节,且是一个奇数,就会存在读取字节不完整的情况,导致乱码。
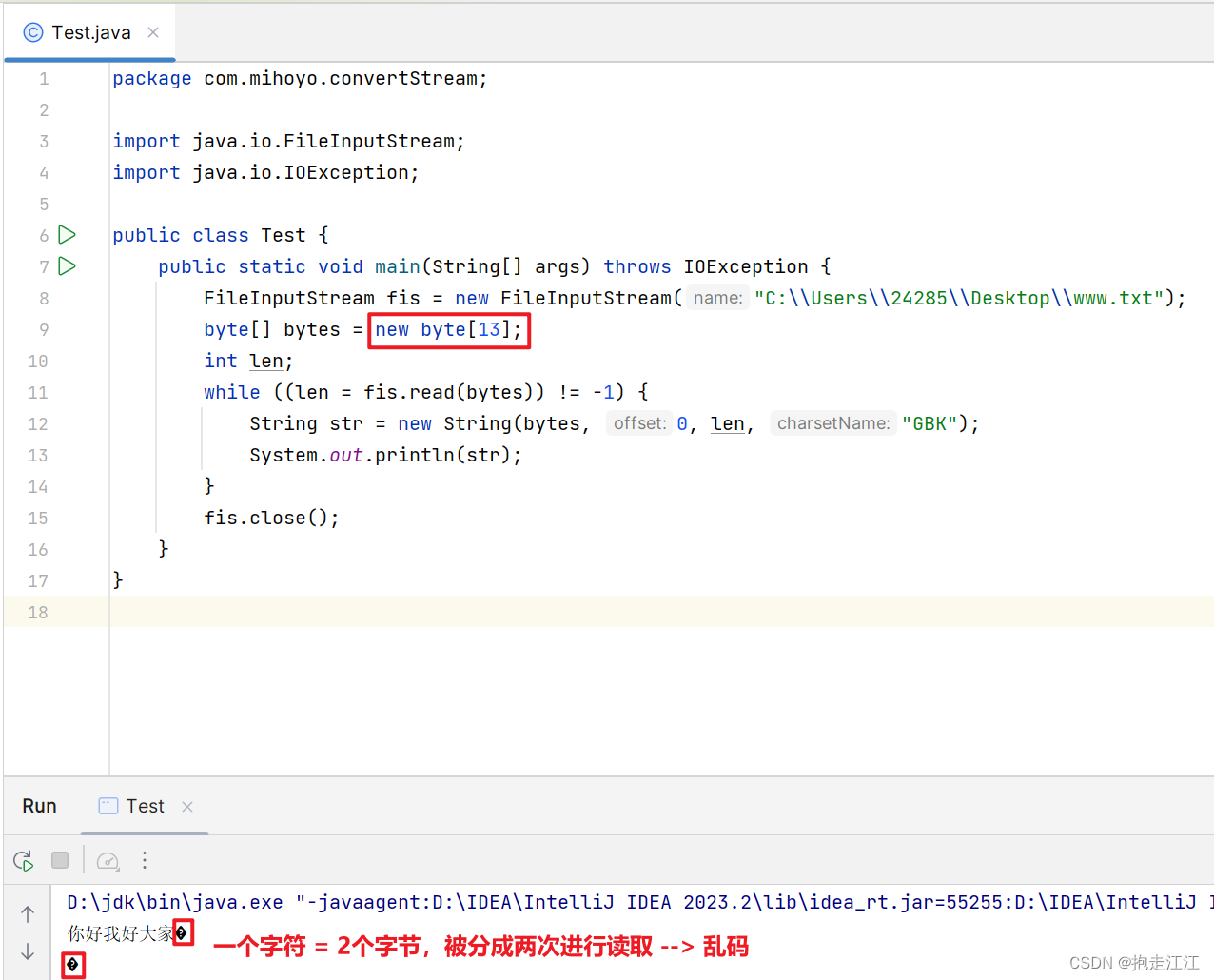
所以为了解决字节读取不完整的问题,我们可以采用字符流进行读取。
字符流每次的操作单位都是一整个字符,在底层:遇到一个汉字,会读多个字节。
但如果用字符流读取,那么方法底层就会用 IDEA的默认编码方式 UTF-8 进行解码。
这时编码(GBK)和解码(UTF-8)方式不统一,就会产生乱码。
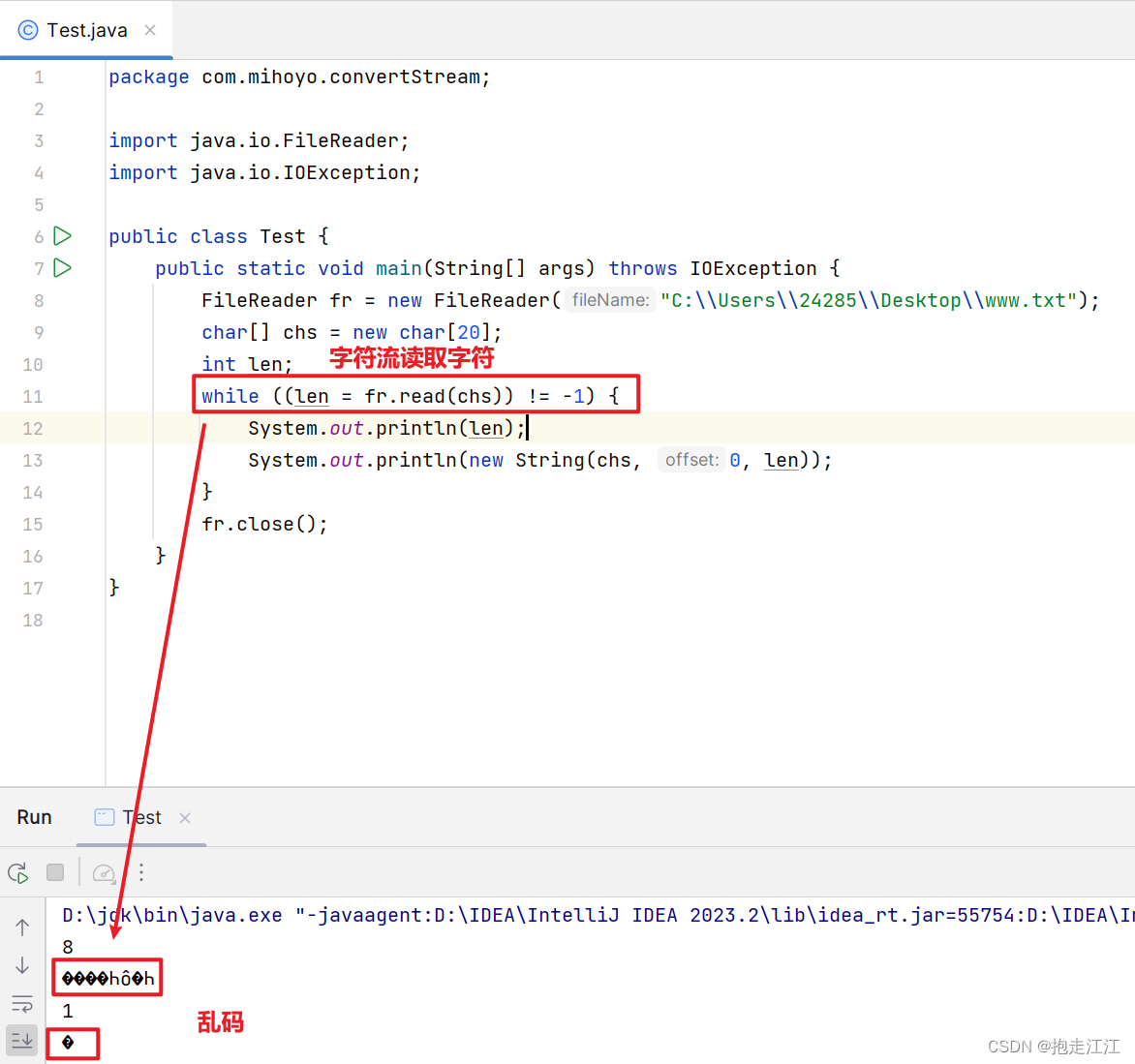
所以真正的解决方式,应该是:用字符流进行读取,但读取的同时要限定为根据 GBK 进行解码。
2.定义
转换流:是字符流和字节流之间的桥梁
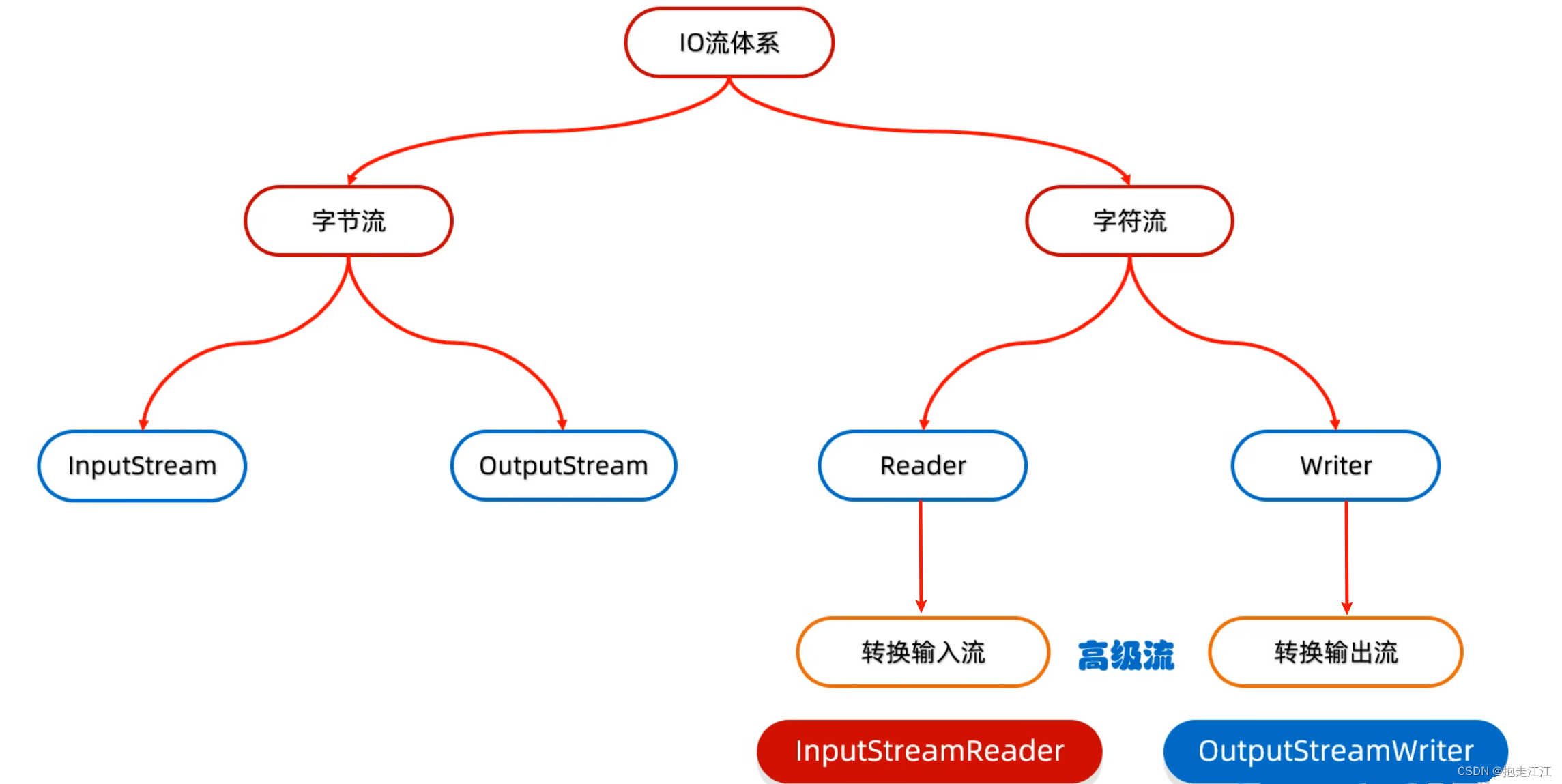
作用:
① 可以根据字符集一次读取多个字节,使得读取数据不会产生乱码(指定字符集进行读写)。
② 字节流想要使用字符流中的方法(比如:readLine 方法)。
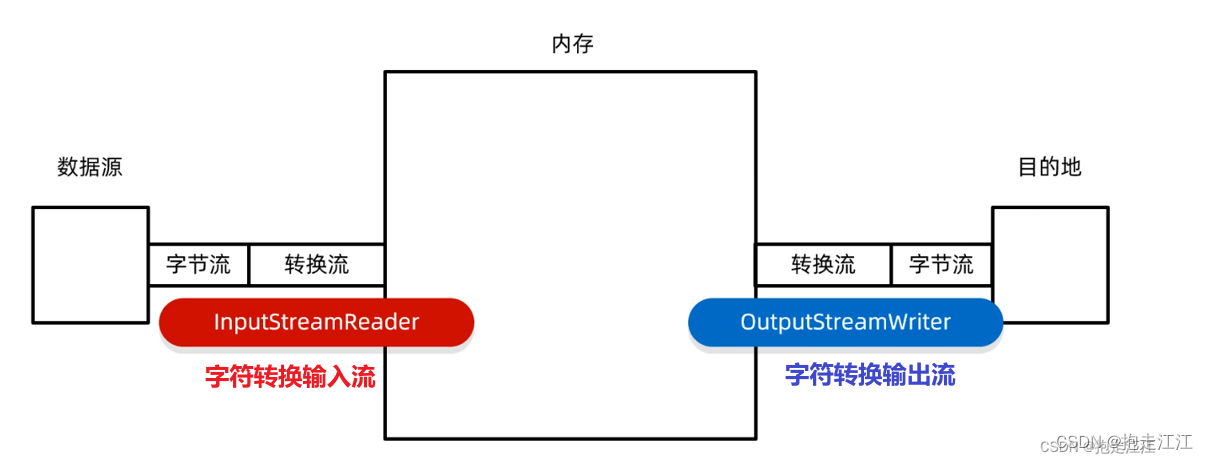
细节:
① InputStreamReader 可以将 字节流 转换成 字符流
OutputStreamWriter 可以将 字符流 转换成 字节流
② 两者本身都属于 字符流 中的一员,父类是 Reader。
3.使用
(1)利用转换流按照指定字符编码读取
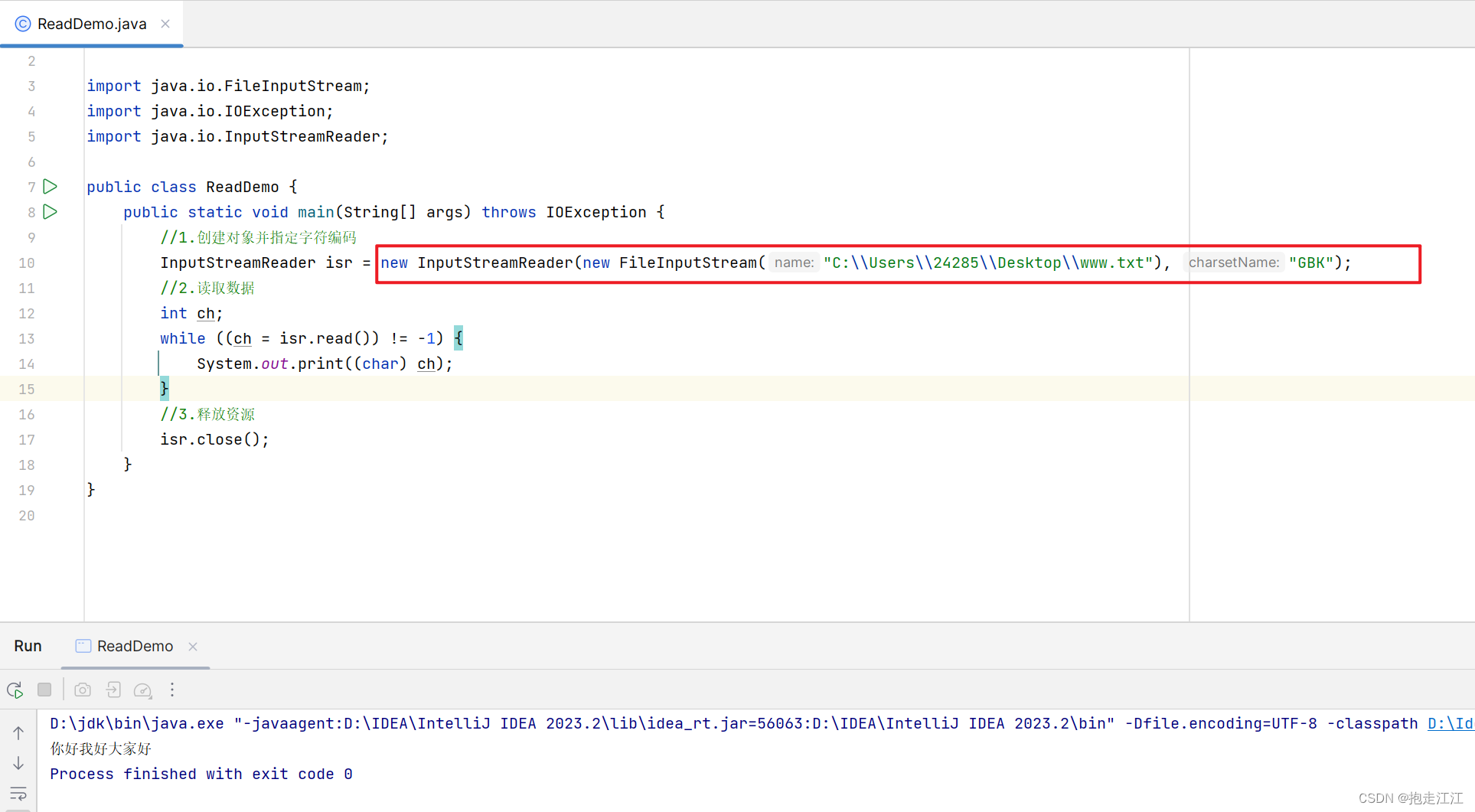
注意:
① 字符集是在转换流 InputStreamReader 的构造方法中添加,不是字节流 FileInputStream的构造方法中。(转换流本身就是字符流中的一员)
② 这种方式了解即可,因为在 JDK11 后,被淘汰了。
替代方案:JDK11后,FileReader 中定义了一个新的构造方法,可以限定字符集来读取数据

而 FileReader 的父类,正是 InputStreamReader。
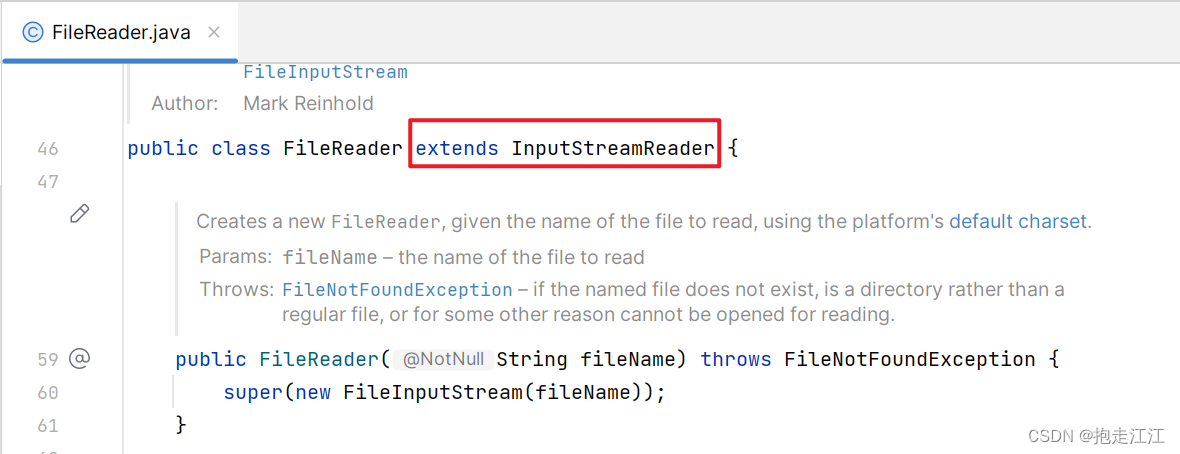
替代写法:
(2)利用转换流按照指定字符编码写出
public class WriteDemo1 {
public static void main(String[] args) throws IOException {
//1.创建转换流的对象
OutputStreamWriter osw = new OutputStreamWriter(new FileOutputStream("C:\\Users\\24285\\Desktop\\www.txt"), "GBK");
//2.写出数据
osw.write("你好你好");
//3.释放资源
osw.close();
}
}运行结果:
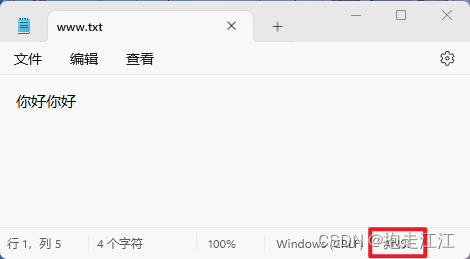
注意:
① 简体中文的 windows 系统中,ANSI 就代表 GBK 字符集。
② 同理,该方式也需了解即可,在 JDK11 后被淘汰了。
替代方案:JDK11后,FileWriter 中定义了一个新的构造方法,可以限定字符集来写出数据
public class WriteDemo2 {
public static void main(String[] args) throws IOException {
//1.创建字符流的对象并指定字符编码
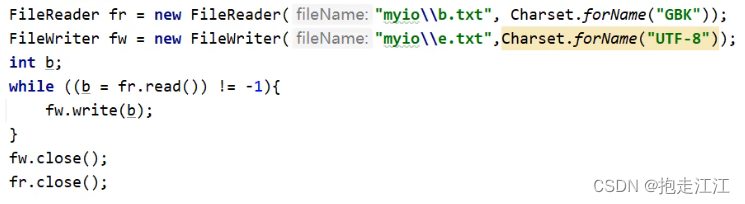
FileWriter fw = new FileWriter("C:\\Users\\24285\\Desktop\\www.txt", Charset.forName("GBK"));
//2.写出数据
fw.write("你好你好");
//3.释放资源
fw.close();
}
}Test1:将本地文件中的 GBK 文件,转成 UTF-8
Test2:利用字节流读取文件中的数据,每次读一整行,且不能出现乱码
① 字节流在读取中文的时候,由于读不完整,是会出现乱码的,但是字符流可以实现。
解决办法:字节流 通过 InputStreamReader 变成 字符(转换)流
② 字节流里面是没有读一整行的方法的,只有字符缓冲流才可以实现。
解决办法:字符(转换)流 通过 BufferedReader 变成 字符缓冲流。
BufferedReader 的构造方法中的参数是一个 Reader 接口,可以利用接口多态传递子类对象。
public class ReadDemo3 {
public static void main(String[] args) throws IOException {
//1.创建字节流
FileInputStream fis = new FileInputStream("IO\\a.txt");
//2.字节流变成字符流
InputStreamReader isr = new InputStreamReader(fis);
//3.字符流变成字符缓冲流
BufferedReader br = new BufferedReader(isr);
//读数据
String line;
while ((line = br.readLine()) != null) {
System.out.println(line);
}
//释放资源
br.close();
}
}转变过程可以一步写完:
BufferedReader br = new BufferedReader(new InputStreamReader(new FileInputStream("IO\\a.txt")));七、序列化流和反序列化流

在实际应用中,会创建很多对象,我们需要将这些对象的信息保存到文件中以持久化保存。
且保证存到文件中的数据,用户无法看懂,即无法修改。
在下次启动程序时,可以从文件中再次读取对象的信息,并加载到程序中。
1.序列化流 / 对象操作输出流
作用:可以把 Java中的对象写到本地文件中

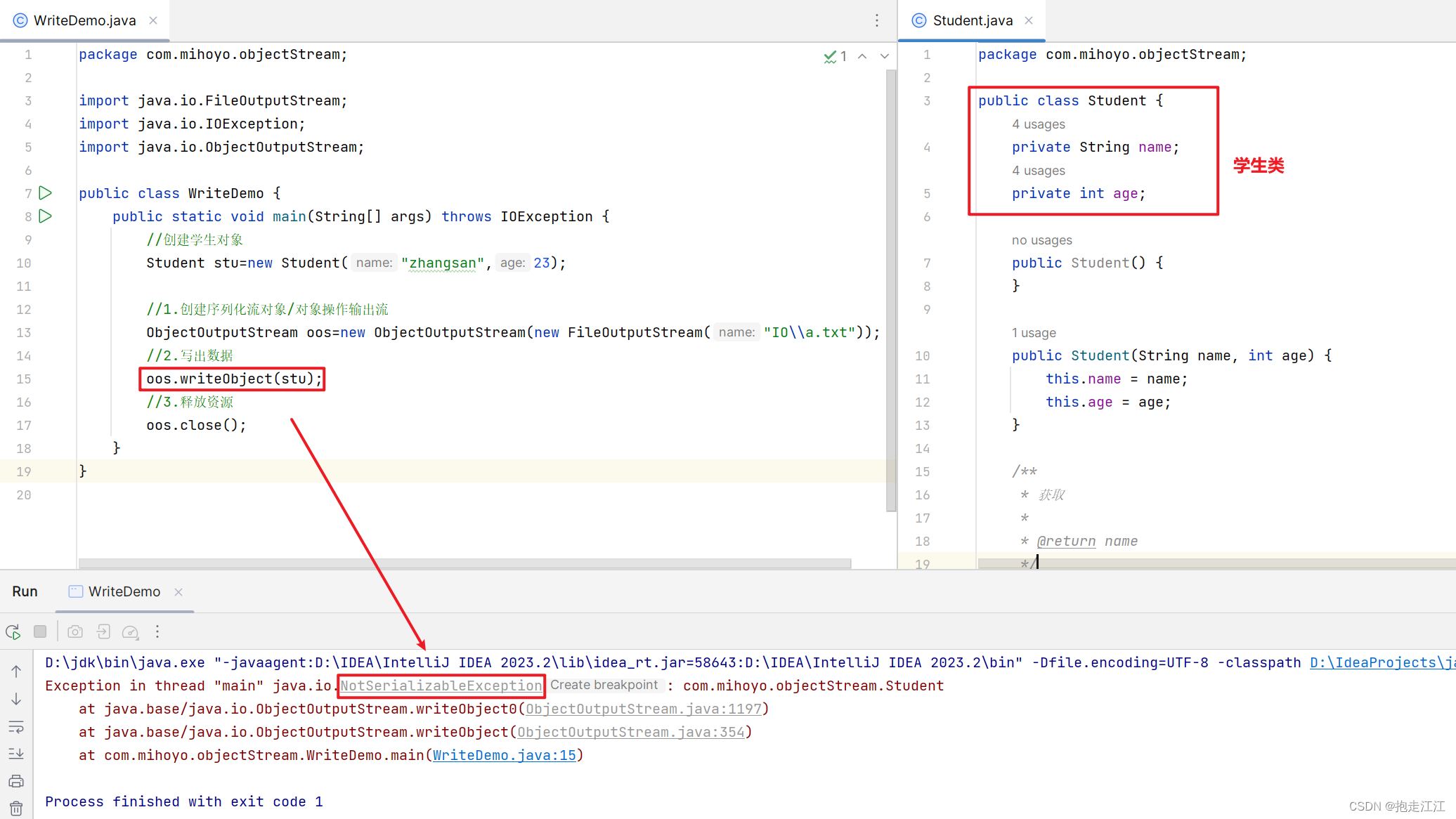
注意:直接使用对象输出流将对象保存到文件中,会出现 NotSerializableException 异常。
解决方案:需要让 JavaBean 类实现 Serializable 接口。
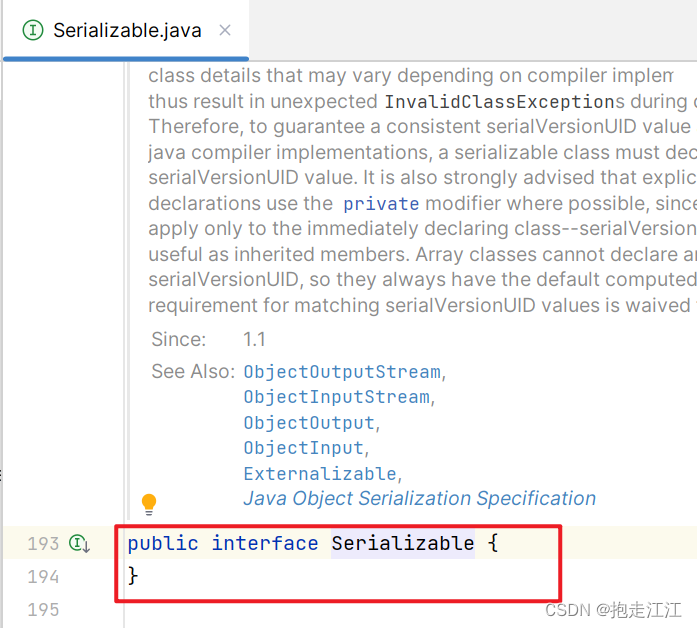
在 Serializable 接口中,没有任何抽象方法,这种接口被称为:标记型接口。(如:Cloneable)
一旦实现该接口,就表示当前类的对象可以被序列化。
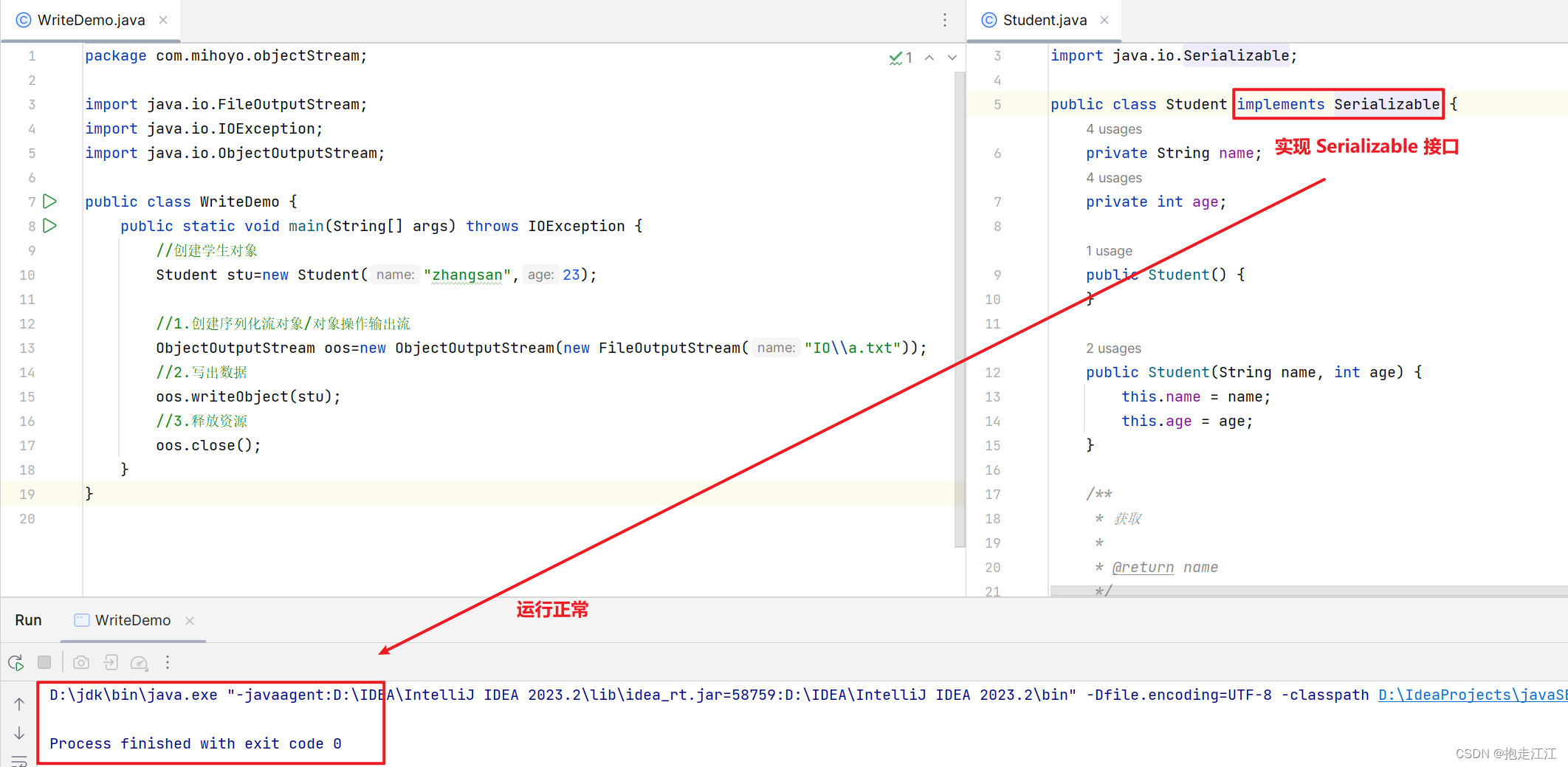
运行结果:
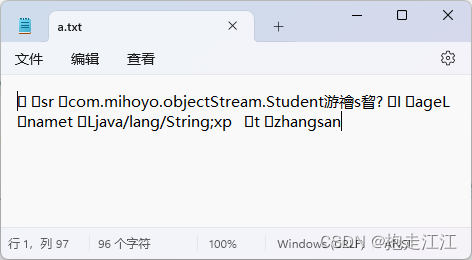
注意:序列化流写到文件中的数据,是不能修改的。
不论修改什么,一旦修改,就无法再次读取回来了。
2.反序列化流 / 对象操作输入流
作用:可以把序列化到本地文件中的对象,读取到程序中来。

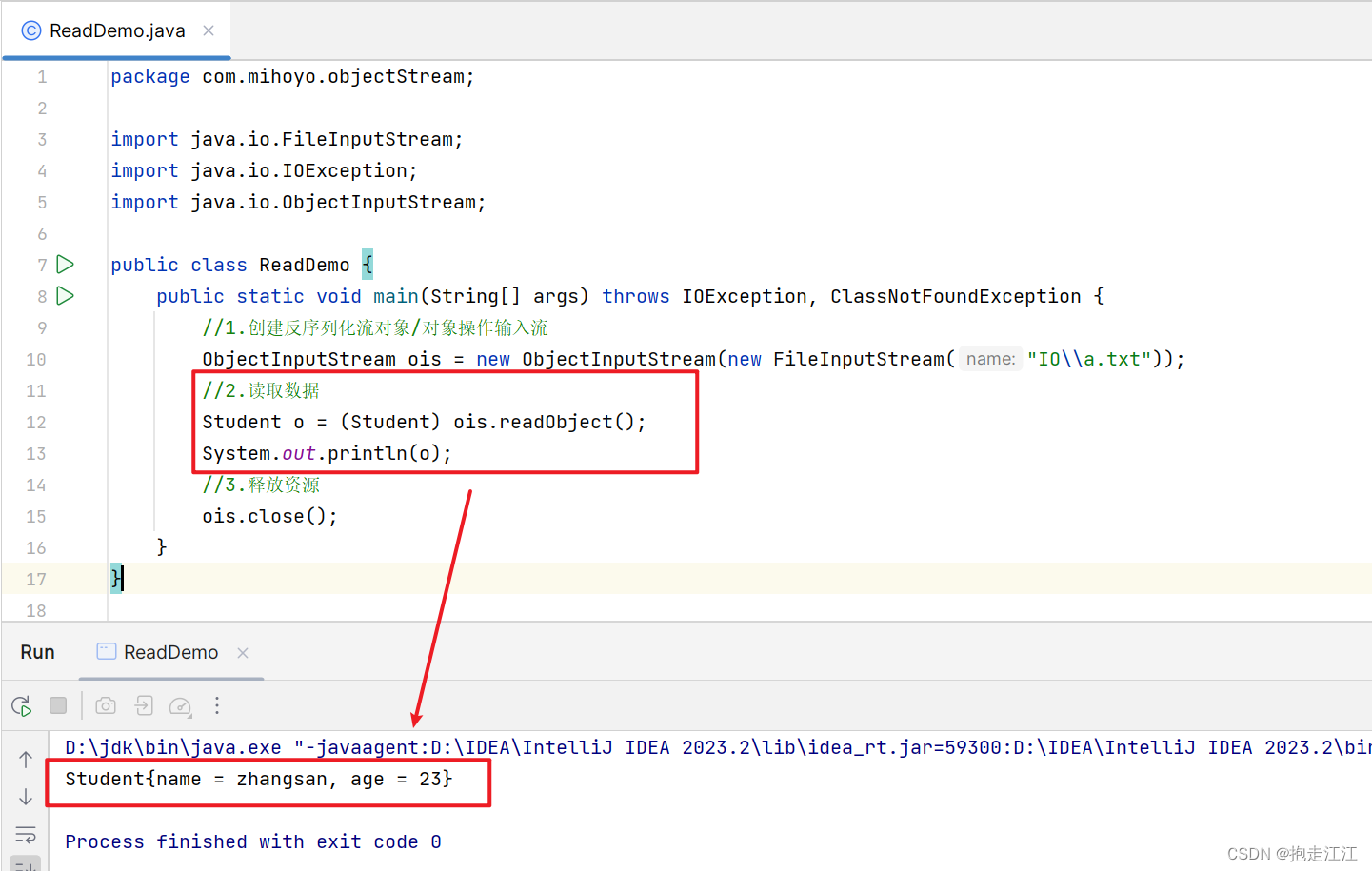
3.细节
(1)序列号
如果一个类实现了 Serializable 接口,就表示这个类的对象是可序列化的。
Java 会在底层根据这个类的所有内容(成员变量,静态变量,构造方法,成员方法等)进行计算,计算出一个 long 类型的序列号(版本号)。
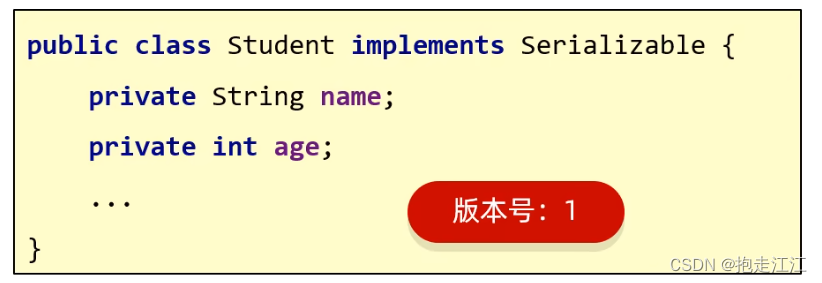
此时,如果创建对象,在对象中,就包含了这个版本号。

用序列化流将这个对象写进本地文件中时,也会将版本号写进本地文件当中。

但如果此时,修改了 JavaBean类, Java 在底层就会重新计算版本号。

这时在进行反序列化,将文件中的对象数据进行读取,就会产生错误。
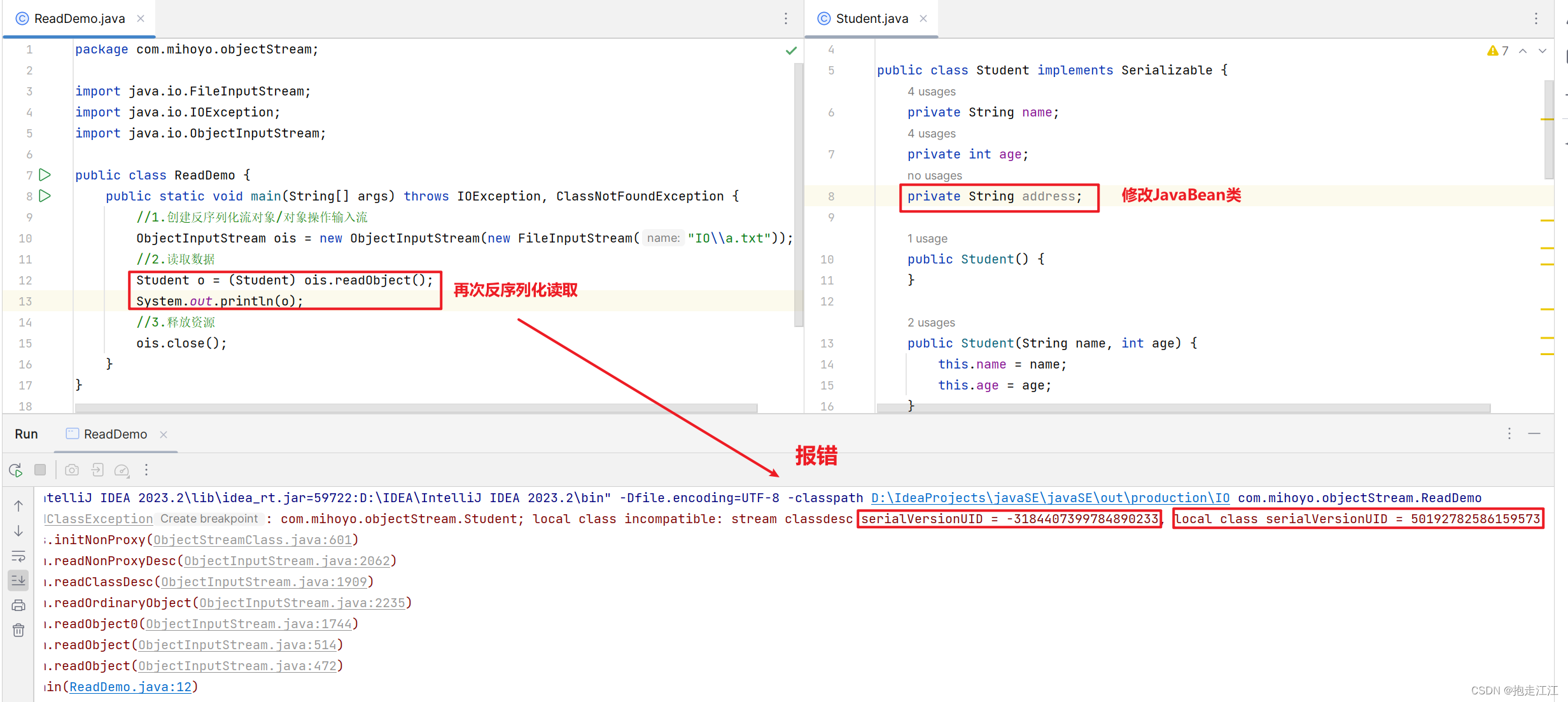
错误原因: 文件中的版本号,和 JavaBean 中的版本号不匹配。
由于在开发中,JavaBean 类不可能不会修改,所以办法只有一个:保证版本号唯一。
解决方案:给 JavaBean 类添加一个静态常量 serialVersionUID(版本号、序列号)
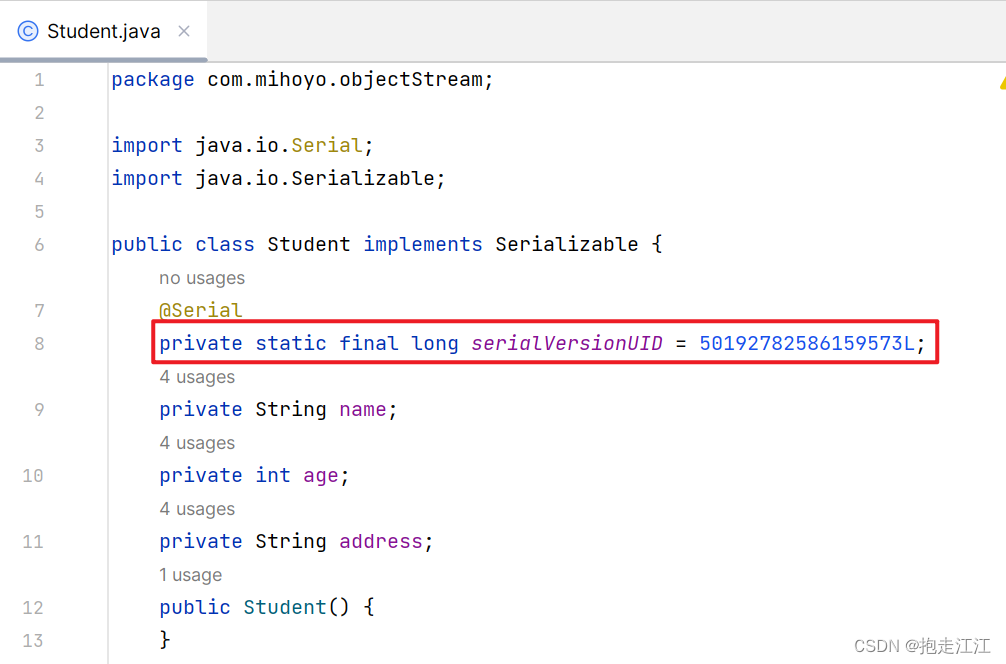
这时,重新将对象数据序列化保存到文件中,无论 JavaBean 类怎么修改,版本号都是该静态常量的值,不会再发生改变。
(2)transient 关键字
Question:如果一个对象的某个成员变量的值,不想被序列化(即不想被写道文件中),如何实现?
解决方案:给该成员变量添加 transient 关键字,该关键字标记的成员变量,不参与序列化过程。
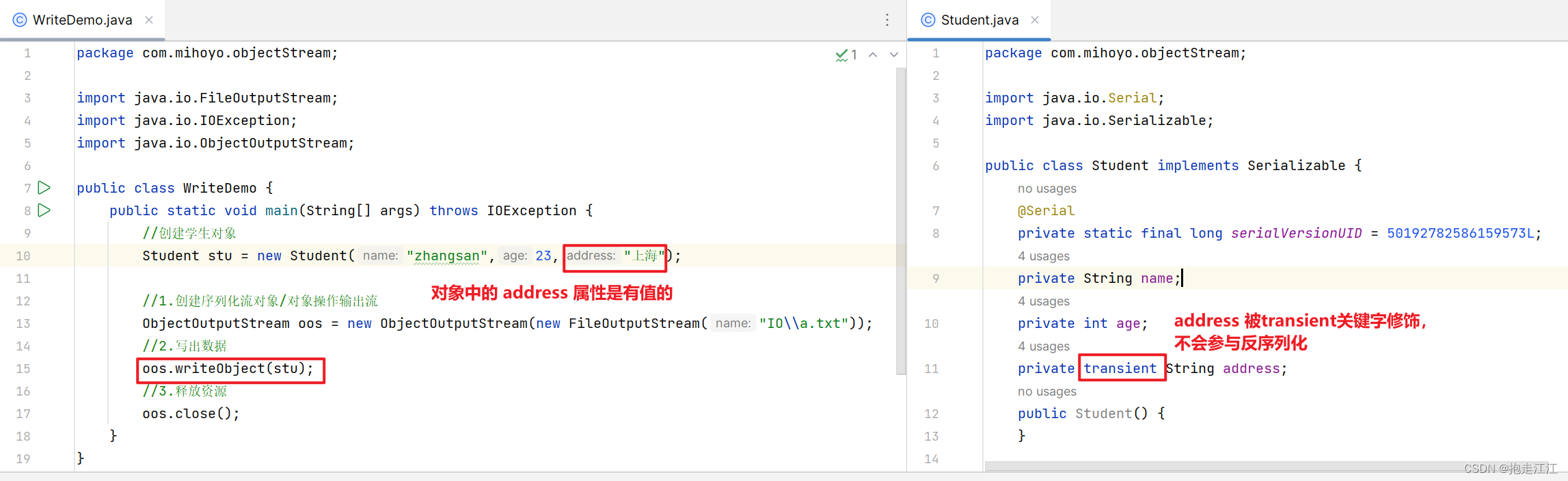
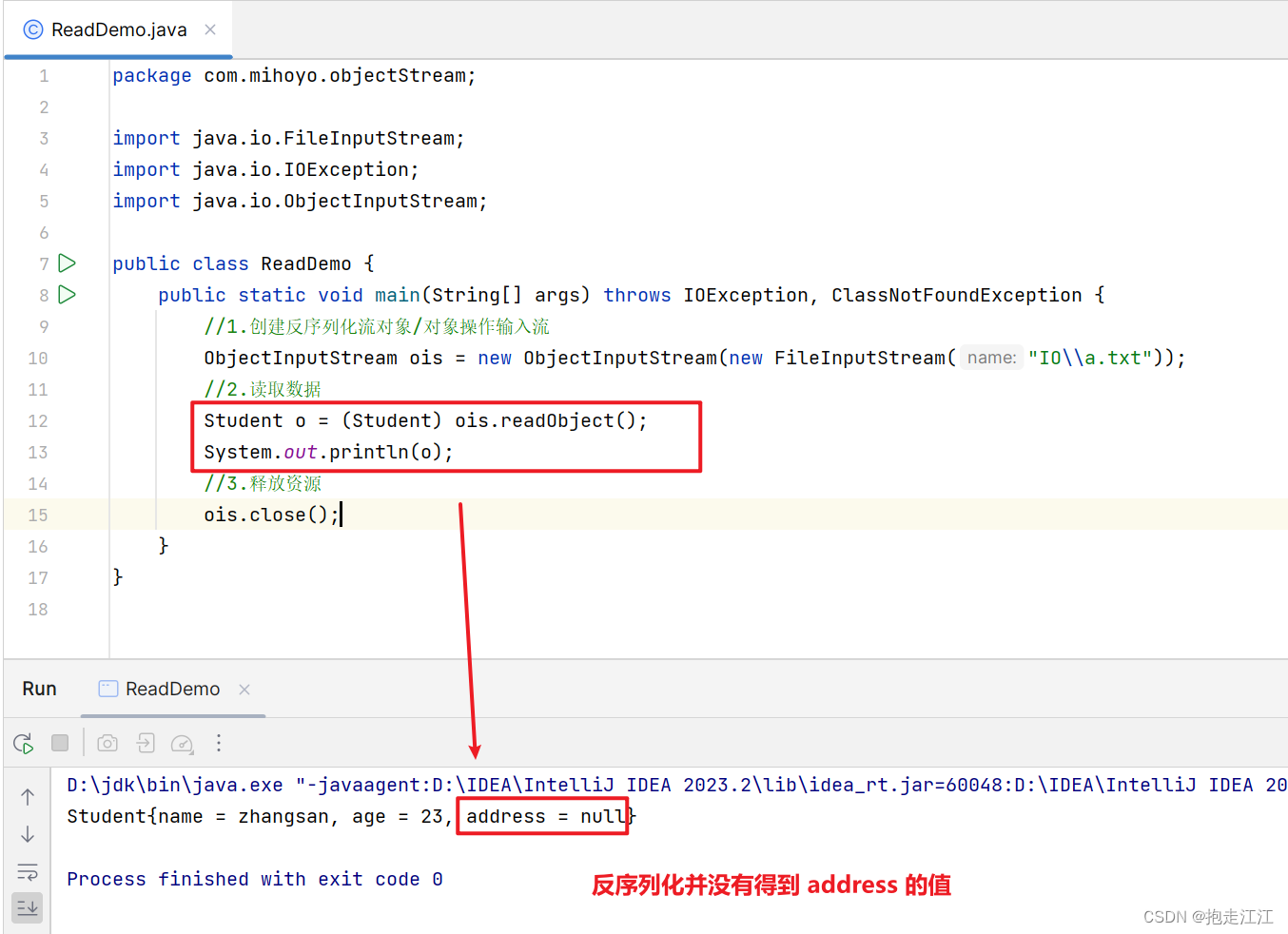
将 stu 进行序列化保存到文件中后,这时在进行反序列化,结果如下:
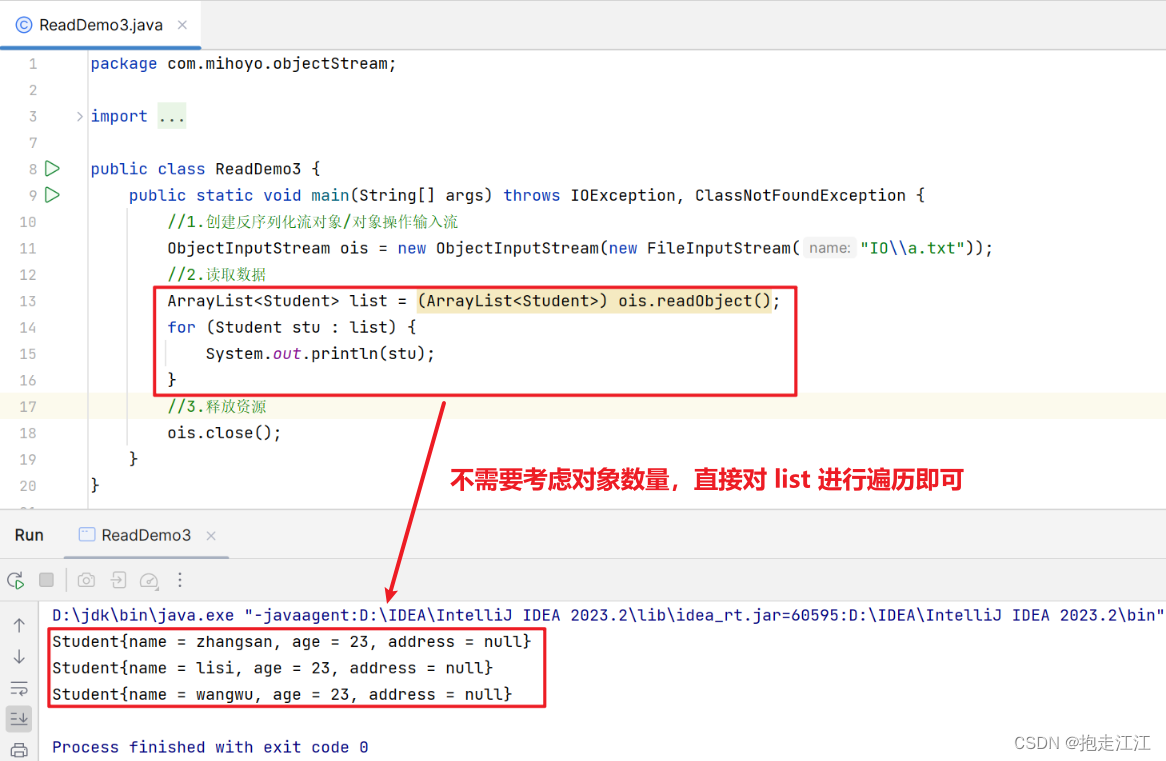
(3)反序列化多个对象
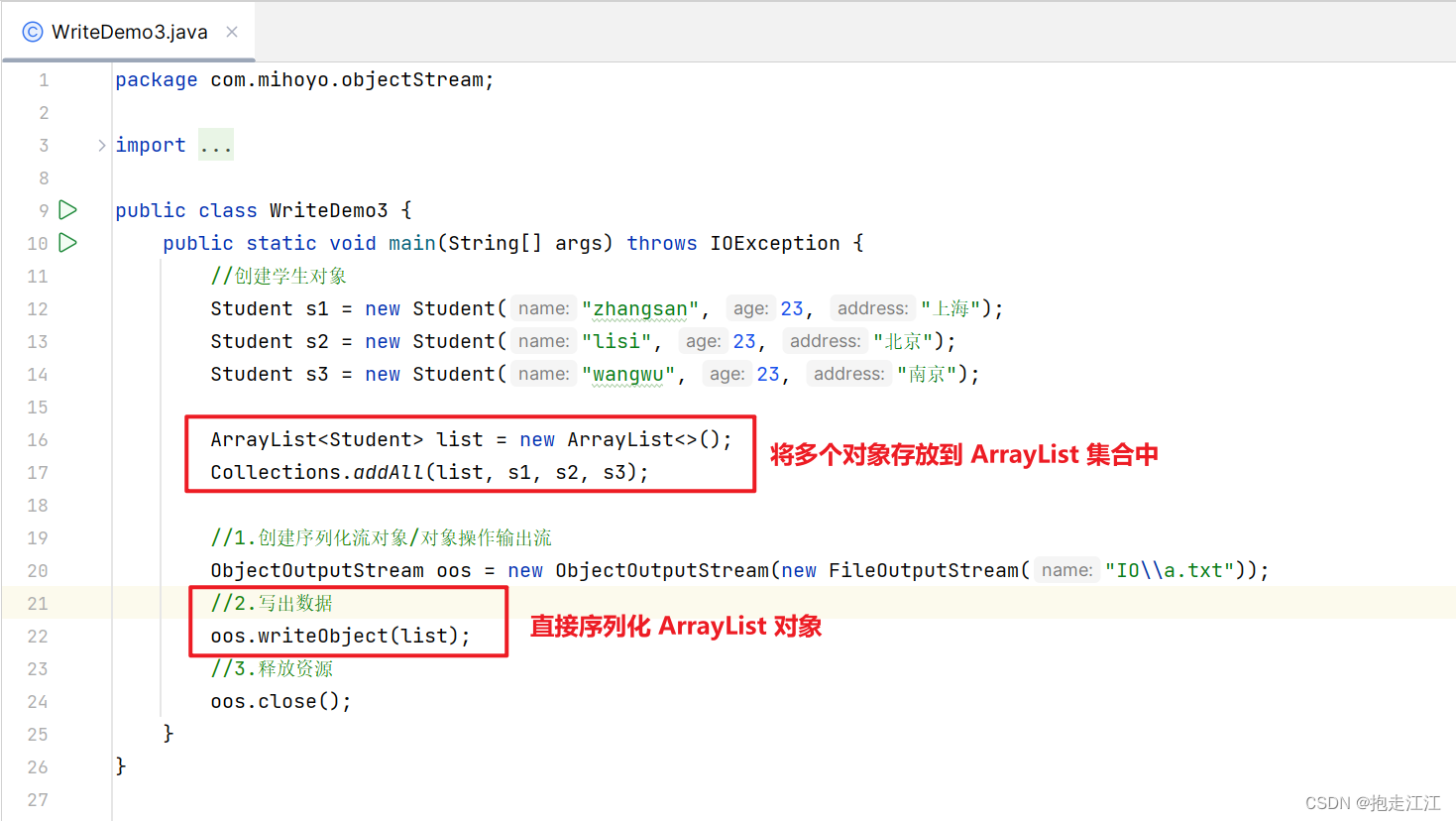
Question:如果自定了多个对象进行序列化到文件中,现在想要反序列化,但不知道对象个数,如何操作?
public class WriteDemo2 {
public static void main(String[] args) throws IOException {
//创建学生对象
Student s1 = new Student("zhangsan",23,"上海");
Student s2 = new Student("lisi",23,"北京");
Student s3 = new Student("wangwu",23,"南京");
//1.创建序列化流对象/对象操作输出流
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("IO\\a.txt"));
//2.写出数据
oos.writeObject(s1);
oos.writeObject(s2);
oos.writeObject(s3);
//3.释放资源
oos.close();
}
}
我们知道,一次 readObject 方法会读取一个对象。
如果我们读到文件末尾,该方法是否会返回 -1或者 null 呢?
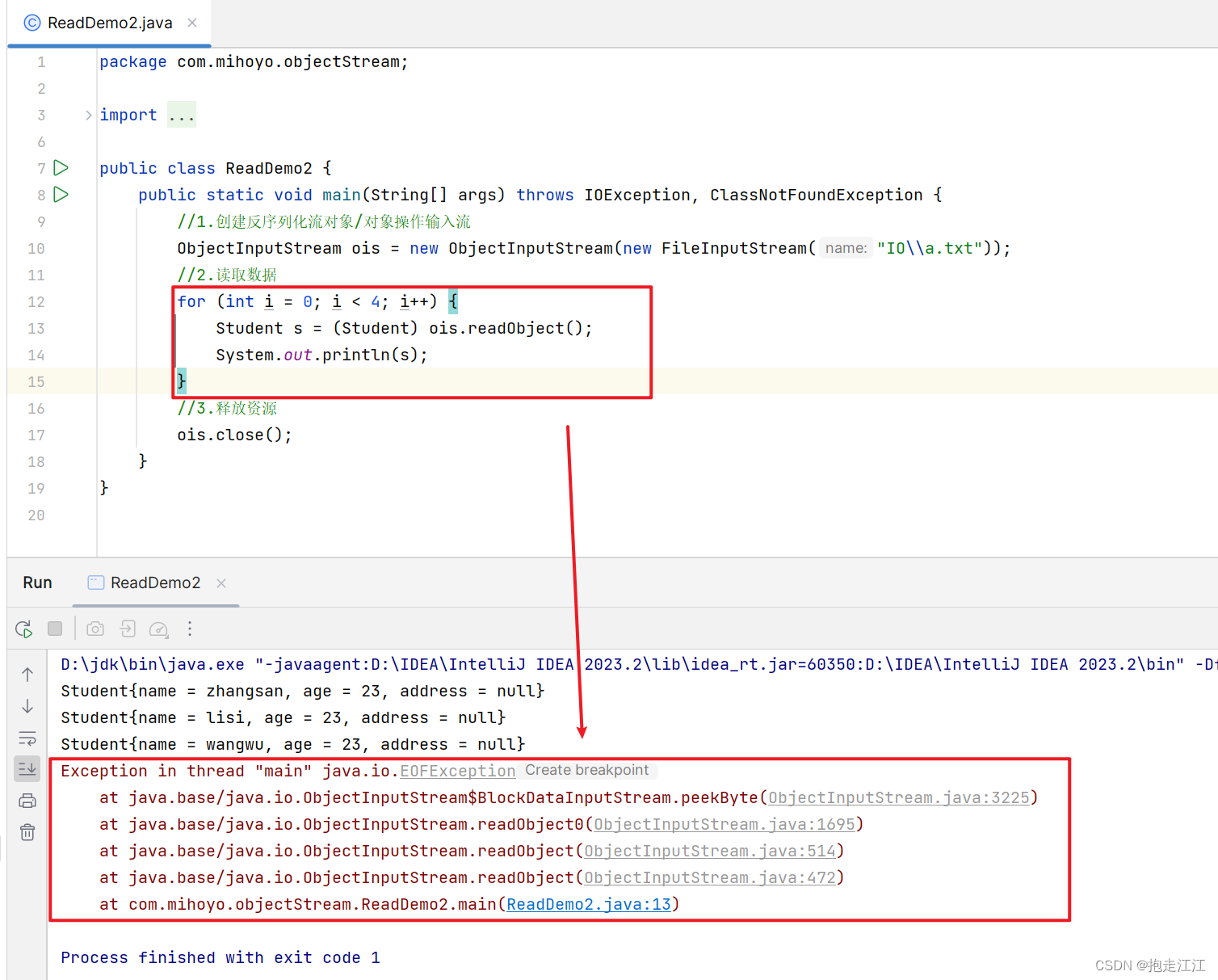
结果发现:当读到文件末尾时,readObject 方法会返回一个 EOFException 异常。
在书写代码过程中,我们不能主动的去制造异常(一直读取,直到遇到异常)。
所以,在将多个对象序列化到本地文件时,规定:
将这些所有的对象,统一存放到 ArrayList 集合当中,然后序列化 ArrayList 对象。
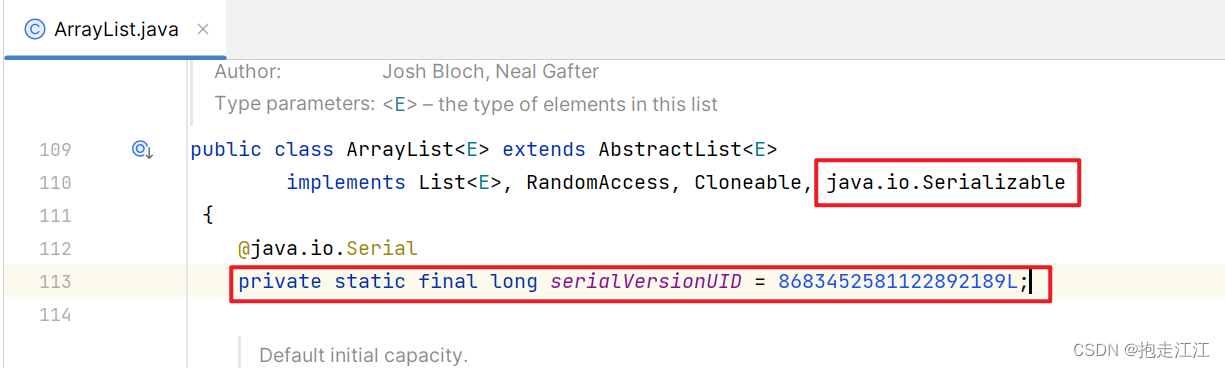
在 ArrayList 类本身,同样实现了 Serializable 接口,并定义了静态常量 serialVersionUID。
这时,在反序列化读取所有对象时,就不需要考虑对象个数,直接对 list 进行增强 for 遍历即可。
八、打印流
特点:
① 打印流只操作文件目的地,不操作数据源(只能写,不能读)。
② 特有的写出方法可以实现:数据原样写出。

③ 特有的写出方法,可以实现:自动刷新,自动换行(打印一次数据 = 写出 + 换行 + 刷新)。
1.字节打印流
(1)构造方法

细节:
① 即使传递的参数为 File 对象或者 String 字符串所表示的路径,方法底层也会根据所传递的路径,创建一个字节基本流的 FileOutputStream 对象。
② autoFlush 参数表示为是否自动刷新,但字节基本流底层没有缓冲区,开不开自动刷新都一样
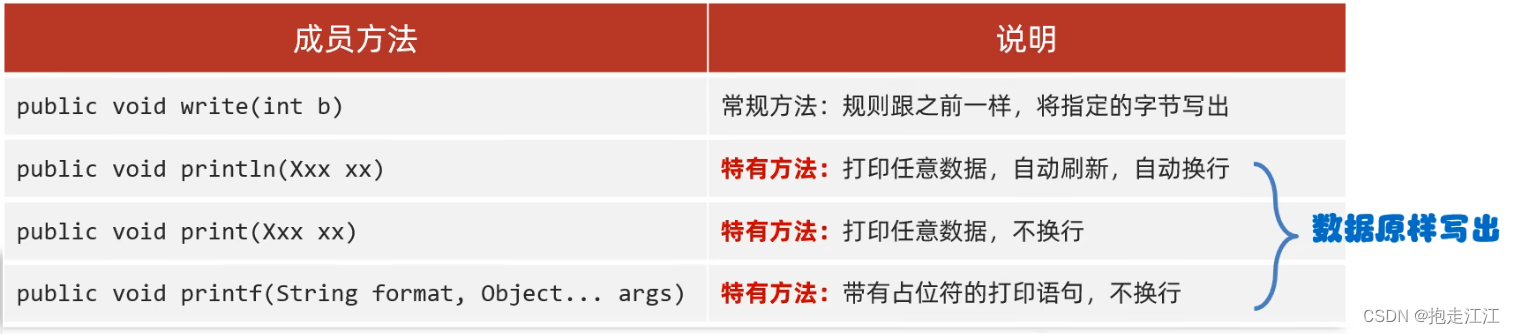
(2)成员方法
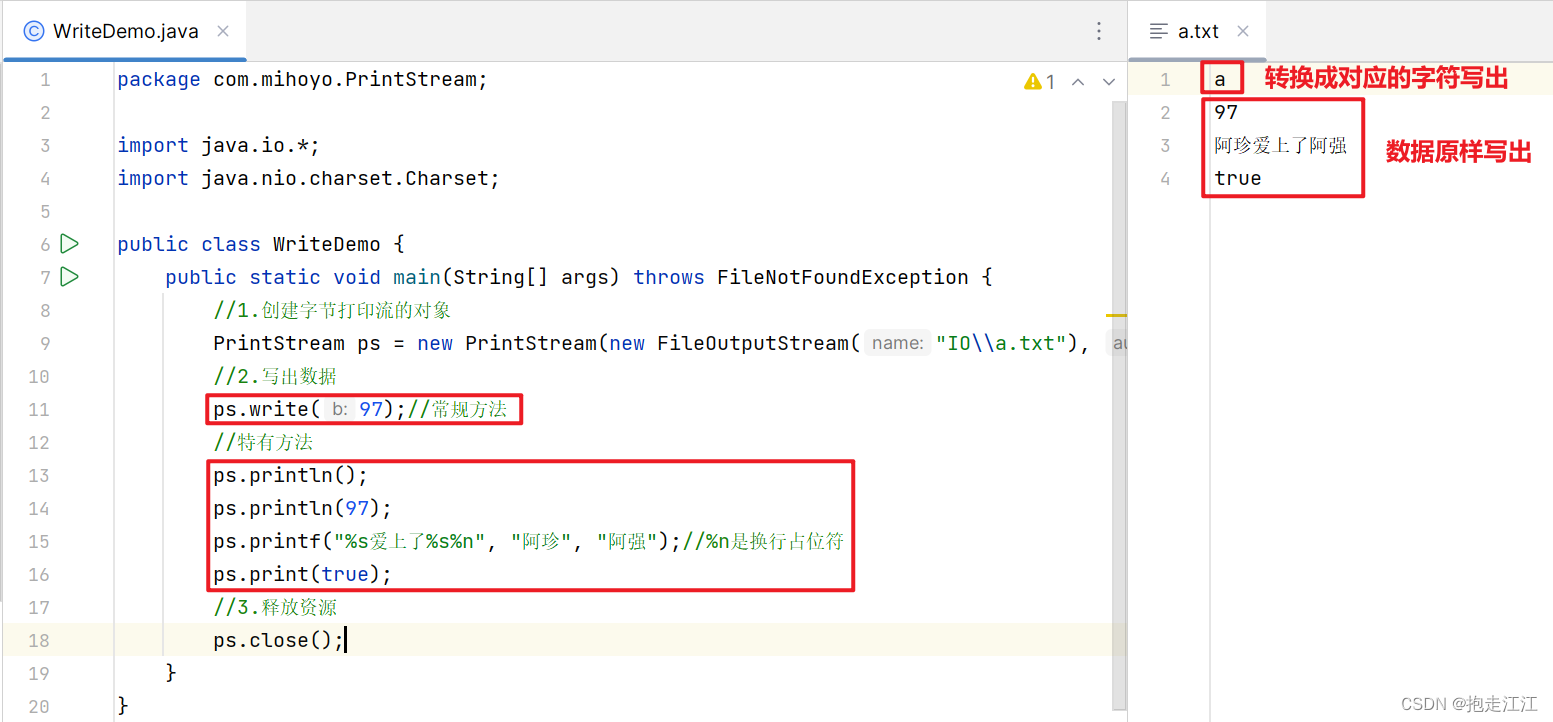
public class WriteDemo {
public static void main(String[] args) throws FileNotFoundException {
//1.创建字节打印流的对象
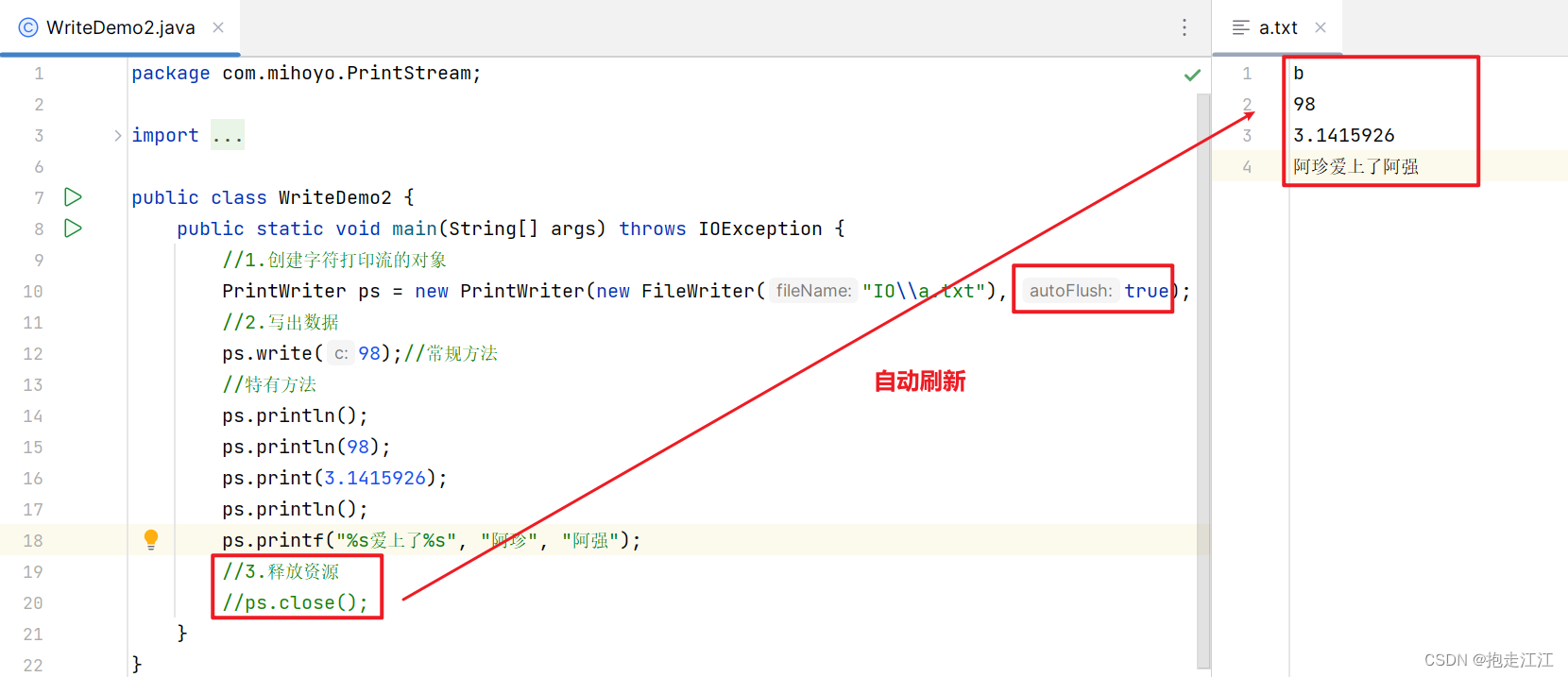
PrintStream ps = new PrintStream(new FileOutputStream("IO\\a.txt"), true, Charset.forName("UTF-8"));
//2.写出数据
ps.write(97);//常规方法
//特有方法
ps.println();
ps.println(97);
ps.printf("%s爱上了%s%n", "阿珍", "阿强");//%n是换行占位符
ps.print(true);
//3.释放资源
ps.close();
}
}运行结果:
2.字符打印流
(1)构造方法

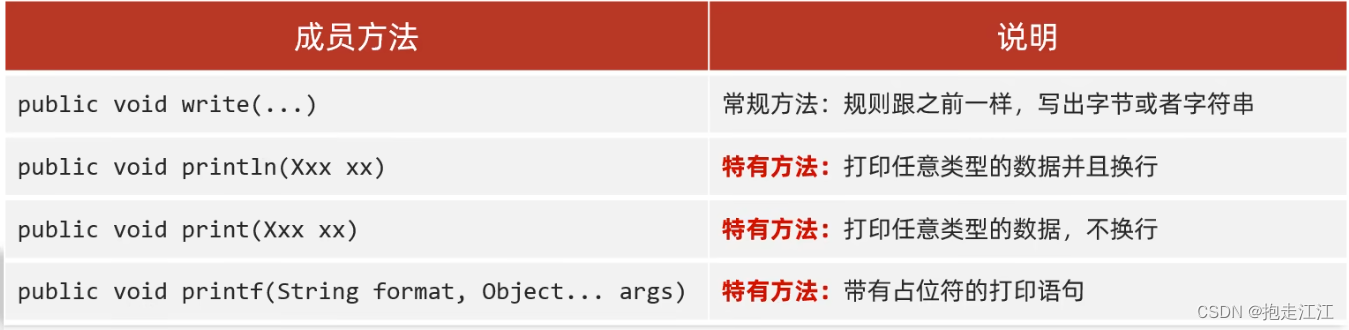
细节:字符基本流底层有缓冲区,想要自动刷新,必须要手动开启(autoFlush 设置为 true)。
(2)成员方法
3.标准输出流分析
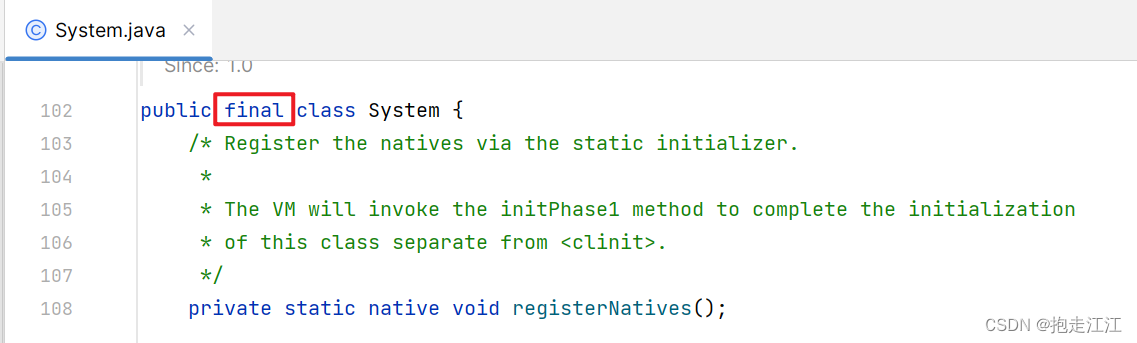
System 类是 Java 已经定义好的一个类,且是最终类,不能再有其他子类。
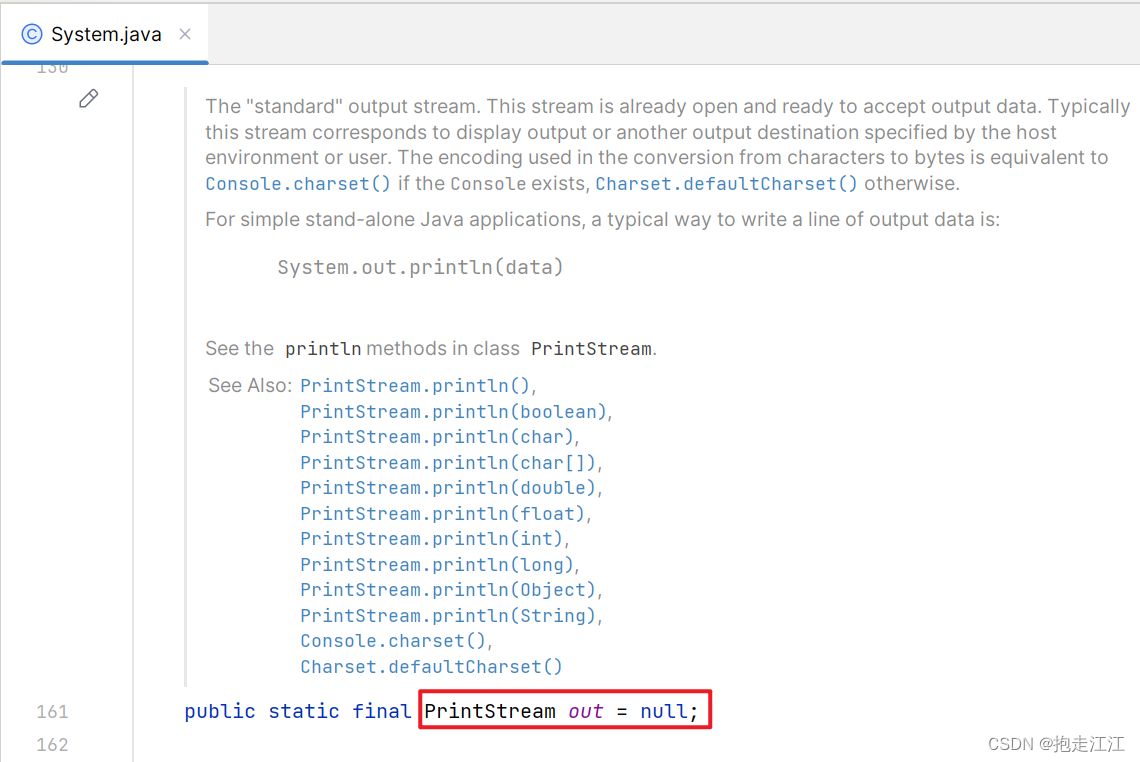
System 类中定义了一个 PrintStream 类型的静态变量 out 。
这个字节打印流的对象不需要我们手动创建,是 JVM 启动之后,自动创建的。默认指向控制台。
这是一个特殊的字节打印流,也被称为标准输出流,所以代码可写为:
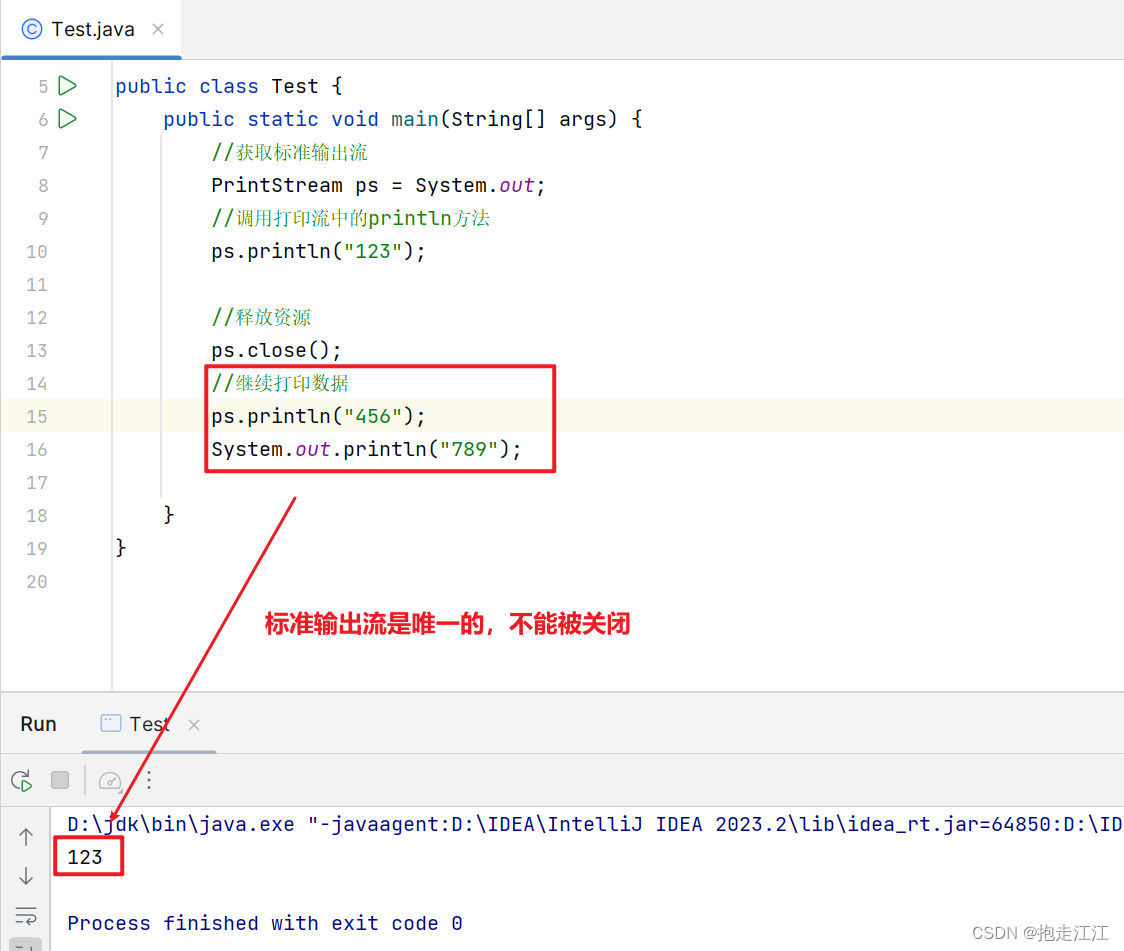
public class Test {
public static void main(String[] args) {
//获取标准输出流
PrintStream ps=System.out;
//调用打印流中的println方法
ps.println("123");
}
}注意:
标准输出流在系统中是唯一的,是不能被关闭的。
如果关闭,将不能在继续打印数据到控制台,除非程序重新执行。
九、解压缩流和压缩流
1.解压缩流
压缩包中的每一个文件或者文件夹,在 Java 中都是一个 ZipEntry 对象。
解压的本质:把每一个文件或者文件夹看成 ZipEntry 对象按照层级拷贝到本地另一个文件夹中。
public class UnzipDemo {
public static void main(String[] args) throws IOException {
//解压的本质:把压缩包中的每一个或者文件夹读取出来,按照层级拷贝到目的地中
//创建一个File对象,表示要解压的压缩包
File src = new File("D:\\aaa.zip");
//创建一个File对象,表示解压到目的地
File dest = new File("D:\\");
//解压
unzip(src, dest);
}
public static void unzip(File src, File dest) throws IOException {
//1.创建一个解压缩流,用来读取压缩包中的数据
ZipInputStream zip = new ZipInputStream(new FileInputStream(src));
//2.遍历获得压缩包中的每一个zipEntry对象
ZipEntry entry;
while ((entry = zip.getNextEntry()) != null) {
if (entry.isDirectory()) {
//是文件夹:需要在目的地dest处创建一个同样的文件夹
//dest : D:\\
//entry.toString() : dest中的每一个文件或者文件夹名(如:aa/,bb/)
File file = new File(dest, entry.toString());
file.mkdirs();
} else {
//是文件:需要读取到压缩包中的文件,并把它们存放到目的地dest文件夹
//dest : D:\\
//entry.toString() : dest中的每一个文件或者文件名(如:a.txt,aa/aa.txt)
FileOutputStream fos = new FileOutputStream(new File(dest, entry.toString()));
int b;
//用解压缩流进行读取数据
while ((b = zip.read()) != -1) {
fos.write(b);
}
fos.close();
//表示在压缩包中的一个文件处理完毕了
zip.closeEntry();
}
}
//3.释放资源
zip.close();
}
}
注意:
① 在 Java中,只能识别 .zip 格式的压缩包
② getNextEntry 方法可以依次读取到该压缩包中所有的文件和文件夹,不需要手动递归,读完返回 null。
③ ZipEntry 类中并没有 isFile 方法判断是否是文件,但有 isDirectory 方法判断是否是目录(文件夹)
④ 解压缩流 ZipInputStream 包装自 FileInputStream,可以进行数据读取。
⑤ closeEntry 方法表示在压缩包中的一个文件处理完毕了。
2.压缩流
压缩的本质:把每一个文件或者文件夹看成 ZipEntry 对象 放到压缩包里。
(1)压缩单个文件
public class ZipDemo1 {
public static void main(String[] args) throws IOException {
//创建一个File对象,表示要压缩的文件
File src = new File("D:\\a.txt");
//创建一个File对象,表示压缩包放在哪里
File dest = new File("D:\\");
//压缩
tozip(src, dest);
}
public static void tozip(File src, File dest) throws IOException {
//1.创建压缩流关联压缩包
ZipOutputStream zos = new ZipOutputStream(new FileOutputStream(new File(dest, "a.zip")));
//2.创建zipEntry对象,表示压缩包中的每一个文件或者文件夹
ZipEntry entry = new ZipEntry("a.txt");
//3.把zipEntry对象放到压缩包当中(只是创建了文件,没有数据)
zos.putNextEntry(entry);
//4.把src文件中的数据写到压缩包中
FileInputStream fis = new FileInputStream(src);
int b;
while ((b = fis.read()) != -1) {
zos.write(b);
}
zos.closeEntry();
zos.close();
}
}
注意:
① ZipEntry 构造方法中的参数,表示压缩包中的路径。
② putNextEntry 方法可以将文件或者文件夹放到压缩包中。只会创建文件,但不会将文件中的数据写进去,仍需要拷贝数据。
(2)压缩文件夹
public class ZipDemo2 {
public static void main(String[] args) throws IOException {
//创建一个File对象,表示要压缩的文件夹
File src = new File("D:\\aaa");
//创建一个File对象,表示压缩包放在哪里(压缩包 D:\\aaa.zip 的父级路径)
File destParent = src.getParentFile();//D:\\
//创建一个File对象,表示压缩包的位置
File dest = new File(destParent, src.getName() + ".zip");//D:\\aaa.zip
//创建压缩流关联压缩包
ZipOutputStream zos = new ZipOutputStream(new FileOutputStream(dest));
//压缩
tozip(src, zos, src.getName());//aaa
//释放资源
zos.close();
}
public static void tozip(File src, ZipOutputStream zos, String name) throws IOException {
//1.进入src文件夹
File[] files = src.listFiles();
//2.遍历数组
for (File file : files) {
if (file.isFile()) {
//3.判断-文件,变成ZipEntry对象,放入到压缩包当中
ZipEntry entry = new ZipEntry(name + "\\" + file.getName());
zos.putNextEntry(entry);
//读取文件中的数据,写到压缩包
FileInputStream fis = new FileInputStream(file);
int b;
while ((b = fis.read()) != -1) {
zos.write(b);
}
fis.close();
zos.closeEntry();
} else {
//4.判断-文件夹,递归
tozip(file, zos, name + "\\" + file.getName());
}
}
}
}
细节:
① zos 构造方法中的路径:
zos 中的路径表示的是压缩包的位置,也就是 D:\\aaa.zip。
但如果以后 源文件夹 名字变成 bbb,那么 zos 中的路径也得变成 D:\\bbb.zip,很不方便。
为此,我们可以通过 src.getParentFile() 获取 源文件夹 的父级路径,也就是 D:\\。
再和源文件夹的名字 src.getName() 进行拼接,就变成 D:\\aaa。
这样如果 源文件夹名字发生改变,zos 中的路径就会自动改变。
② tozip 参数三的原因:
直接输出 file 对象,打印的是绝对路径(D:\\aaa\\aa\\a.txt)
通过 getName 方法,打印的是文件名(a.txt)
而 ZipEntry 构造方法中的参数,表示压缩包中的路径,所以需要的是:aaa\\aa\\a.txt。
所以首次递归传入 src.getName(),也就是 aaa。
后续遇到文件夹,再通过递归传入 name + "\\" + file.getName(),也就是aaa\\aa
③ putNextEntry 将文件放入压缩包中时,如果 entry 的路径中父级路径不存在,会自动创建父级路径。
所以在 tozip 方法中,遍历到文件夹直接递归即可,不用创建文件夹。
十、常用工具包
1.Commonis-io
Commonis-io 是 Apache开源基金组织提供的一组有关 IO 操作的开源工具包。
作用:提高 IO 流的开发效率


public class Test {
public static void main(String[] args) throws IOException {
File src = new File("IO\\a.txt");
File dest = new File("IO\\b.txt");
//复制文件
FileUtils.copyFile(src, dest);
}
}
导入 jar 包后,原先复杂的操作,现在一行即可搞定。
2.Hutool
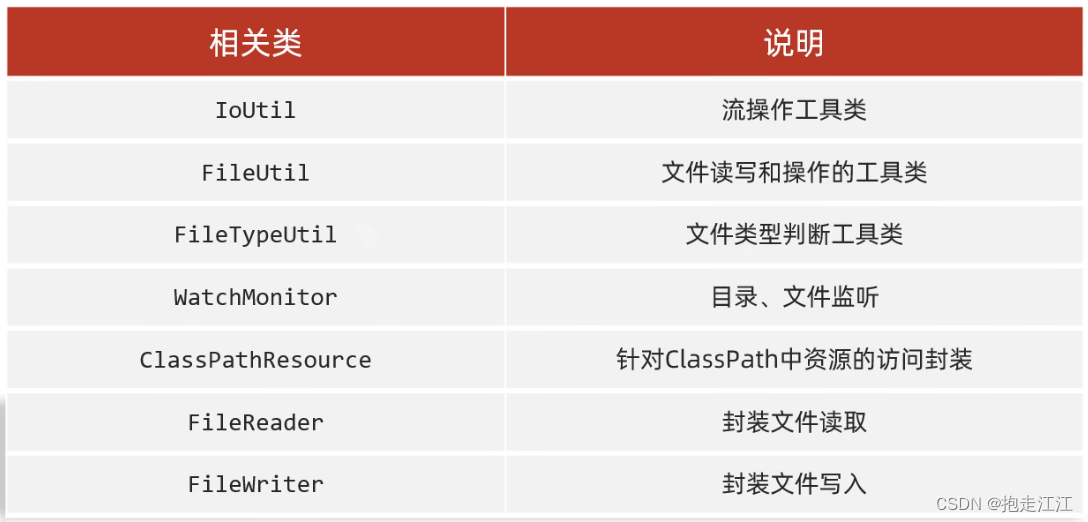

详细用法请参考以下网址:
官网:https://hutool.cn/
API文档:http:// https://apidoc.gitee.com/dromara/hutool/
中文使用文档:https://hutool.cn/docs/#/

![[FreeRTOS 基础知识] 信号量 概念](https://img-blog.csdnimg.cn/direct/376b4922e6444895adcbc65f7fdc9450.png)
![[FreeRTOS 内部实现] 信号量](https://img-blog.csdnimg.cn/direct/17882d1734e242d1b0e959a0d5afbaec.png)